Final Exam¶
Prep¶
- Design section of the paper, no need to read evaluation part
- Slides (not enough)
- Textbook reading
Exam Style¶
- 50%: Multiple-choice questions
- 30 %: Some obvious questions (medium questions, fundamental concept questions)
- 20%: 3 hard questions: design questions like design a system (Your friend thinks the system suck. And my design is… Should we implement this? You can say yes and why, or no and describe scenario)
- Some are really hard from practical system
From Piazza’s Fellow¶
There’s a ~~review~~ Q&A session 1-2 days before the exam, more details TBD.
- This session is not recorded due to needing permission from all students.
- Prof Al-Kiswany will also be available for office hours on request since the exam happens pretty late. So if you can't make it to the session, request hours.
- I didn't write down when the sample final would be released, but I think it's after classes finish?
What material is testable?
- Core material is the slides + anything written/drawn on the board
- Textbook content -> Some of the sections are not covered/unrelated, if you're unsure ask Prof Al-Kiswany
- Papers -> focus on design, some papers' related works section are relevant, skip evaluation
What should you expect on the exam?
The exam is worth about 100 points. There are 3 main types of questions:
-
Easy
-
Medium -> asks about the material itself (e.g., A1's identify which RPC calls are dupes, errors, successes)
-
Hard -> usually 3 on the exam; design-based
The hard questions will be something like "Friend wants to modify Raft to do X. Does this change work? Why or why not?". They are worth around 15-20 marks total. There is some leniency on marks if it seems you're on the right track.
The exam is also 50% MC, but these require some time to think and answer.
Final Note:
The average GPA is usually above 81% and around 40 students are in the 90s.
Questions¶
- In RPC, if a server has executed the request and sent back the result but before the client gets the chance to record it and the client crashes, when the client reboots it sends the same request again but with a new conversation id now. In this case, the server finds the conversation id is different, it will executed the same request again?
Sample Questions¶
-
Problem 1 (hard question)
-
In Google file system, an unsuccessful writes to a file can make a region of a file “inconsistent”. What does “inconsistent” mean?
It means the data is not the same across the replicas. If the client reads the data from different replicas it will see different versions of it.
-
Extend the GFS design to avoid this case, such that in your new GFS design, failed writes do not modify any replica of the chunk.
After receiving the data in the buffer for each replica, each replica copies the chunk as a temporary chunk and update on this chunk. Then we do an atomicity replacement of the chunk. Only after every replica is successful the primary replies to client. Otherwise, report failure back.
We need to use 2PC here. After the shadow copy, the primary sends a
Preparecommand, and if only if all replicas replied with yes, the primary as a coordinator sends aCommitmessage. You must write to the disk (the shadow/temporary chunk) before you tell the Primary you are "Prepared.” The Primary tells everyone to "Swap." The chunkservers perform a metadata rename (Old_Chunk → Deleted, Shadow_Chunk → Official).
-
-
Problem 2 (hard question)
In 2PC if a participant crashes and has a disk failure that corrupts the log files. The failure causes the information for one transaction, including the participant vote, to be lost. When the participant boots back, will this failure cause correctness? or availability problems for 2PC?
It depends on when this failure happens. If this failure happens before sending the vote for Prepare back to the the coordinator, there will be no issues at all as if the coordinator didn’t hear back from any of the participants, it will timeout and abort the transaction. If the participant fails after it votes a YES for prepared and all participants voted YES, the coordinator will send the commit message. However, after timeout, the coordinator won’t hear anything such that ACK from that failed participant as it fails and the log is corrupted. In this case, the coordinator will not clean up the log message but keep trying send the Commit request to that participant. Only after it replies with ACK the whole transaction is done.
There is no correctness issue because the locks are persistent and are acquired/written to disk before the L2 (Prepare) log entry.
- Mechanism: Even though the L2 log entry is lost (meaning the participant "forgets" the transaction details), the physical lock on the data remains on the disk.
- Safety Guarantee: Since the lock is still held, no other transaction can read or write to that specific data. This prevents "Dirty Reads" or "Lost Updates." The system never enters an illegal state where conflicting data is visible; it simply prevents any access to that data at all.
This failure causes a significant availability issue that typically requires manual intervention.
- Mechanism: Upon reboot, the participant finds a locked record but no corresponding transaction log (L2) to tell it how to resolve the lock.
- The "Deadlock" State: The Coordinator will repeatedly retry the Commit/Abort command. However, the participant cannot acknowledge (ACK) or fulfill the request because it has no record of the transaction.
- Result: The data remains "orphaned" and locked indefinitely. The affected rows/resources are unavailable to the entire cluster until an administrator manually clears the locks or uses a database repair tool.
- Problem 3 (medium)
Explain how MapReduce handles double execution of:
-
Mappers
The master will only take the first complete result from the mapper and give it to the reducer, and ignore another one.
When a Mapper completes, it reports the locations of its intermediate files to the Master. The Master only records the locations from the first instance of the task to complete. Any subsequent "Task Complete" messages for the same Task ID are silently ignored, ensuring Reducers only pull data from a single, consistent source.
-
Reducers
When reducer outputs to the storage, it will save to a temporary file. Only after the output file is completed an atomicity rename to the final output file name will be performed. The result from another reducer will be ignored.
-
Problem 4 (medium)
You are given a large collection of documents. Each document has a unique ID and contains some text. Using MapReduce, build an inverted index that maps each word to the list of documents in which it appears in. If a word shows twice in a document, the document ID should show once in the output.
Map (doc_ID, content) // doc_id is the document ID, and “content” is the content of the document { val tokens = Tokenizer(content) distinctTokens = tokens.distinct for word in distinct: Emit(word, doc_ID) } Reduce (word, it) // it is an iterator of values. { val sortedDocID = it.toList.sort(ascending=True) Emit(word, sortedDocID) } -
Problem 5 (medium)
Consider the lineage of versions for an object D in Dynamo. Starting from D2, present how the system may end up with versions D3 and D4. State what failures happen and how requests are processed.
In the presence of a network partition, two clients in different partitions read the same object D from different replicas Sy, Sz at the same time, that is, D2. Each of them performs some operations on object D2, therefore creating object D3 and D4 concurrently.
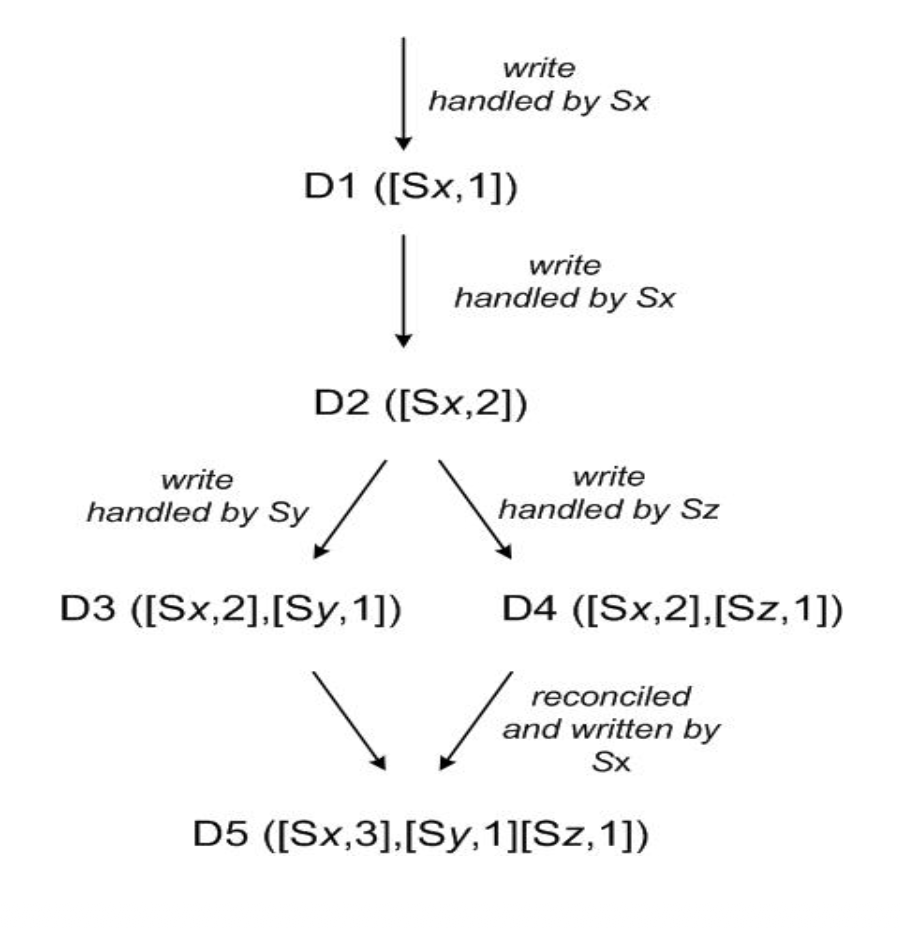
-
Problem 6 (medium)
Xerox RPC has at-most-once semantics. When a client times out and repeats an RPC calls:
-
How can the client distinguish between a slow server and a server that crashed and restarted?
Initially the client cannot distinguish between a slow server and a server that crashed and restarted. However, when client sends request to server again with same set of parameters, the server will find that
fidnot in its table, and it will tell the client function not found. By that time the client knows a server crashed and restarted.The client cannot tell from a timeout alone whether the server is slow or has crashed. If it retransmits the RPC using the old fid and the server responds that the function does not exist, the client can infer that the server rebooted, because after restart the server generates new fids and the old binding becomes invalid.
-
Why is it important for clients to detect if a server that crashed and restarted? What will the client do differently when detecting that a server rebooted?
It is important for clients to detect if a server had crashed and restarted because it needs to consider the case whether the server has executed the request before it crashed. And it has detected the server rebooted, it needs to rebind the functions as the old function ids are gone.
Detecting a reboot is important because the client’s old binding information is stale after the server restarts. The client must not keep retrying with the old fid. Instead, it must rebind to the server, obtain the new fid for the function, and then reissue the RPC.
-
-
Problem 7 (medium)
Your goal is to synchronize the clocks of two machines that are network connected. More precisely you try to synchronize the clock of machine A with that of machine B. Describe a complete solution to synchronize the clock of machine A match that of machine B. Show the derivation of the offset formula. You can assume that the network delay from A to B (DAB) is the same as the network delay from B to A (DBA).
We will use NTP to synchronize the clock of machine A with that of machine B. Let T1 be the time A sends request to B, T2 be the time B receives the request, T3 be the time B sends the reply to A, and T4 be the time A receives the reply. The offset can be calculated as [(T2-T1)+(T3-T4)]/2. Since the network delay between A and B is same, the network latency is eliminated in the formula. Therefore, the difference is a more correct estimate offset between A and B.
Let d be the actual difference between A and B
T2 = T1 + DAB + d, which means that d = T2 - T1 - DAB
Think about it, T1 + DAB = T2 - d (based on A’s time)
T4 = T3 + DBA - d, which means that d = T3 + DBA - T4
Think about it, T3 + DBA = T4 + d (based on B’s time)
Thus, 2d = T2 - T1 - DAB + T3 + DBA - T4 = T2 - T1 + T3 - T4 as DAB = DBA
If B is "ahead" of A by d (a positive number), then A must be "behind" B by that same amount.
If the offset > 0, it means the A is behind, and its clock needs to speed up a little bit to catch up that of B. If offset < 0, it means A is ahead of B, and so its clock needs to slow down a little bit.
-
Problem 8 (medium)
You are designing a high-performance service and realized that pure eventual consistency as well as read-your-write consistency can work with your application. Which one of these two will you implement in your system? Why?
This is a bit confusing as the context is not enough to tell what kind of application it is. read-your-write consistency is stronger than pure eventual consistency as any subsequent read after write by the client will be the latest write performed by the client. If this is important, then we should use read-your-write consistency as the read/write will be consistent to you. However, if you move to a different location, it is very likely that same replica as before is being used as it contains the most recent data performed by you, depending on your location the delay may be longer since that replica is what you usually read from and write to. But by the end the system will converge. If this is tolerable and not an issue you are concerning, pure eventual consistency is more than enough as it provides lower latency and high availability.
If both consistency models are acceptable for the application’s logic, I would implement Pure Eventual Consistency, since it is easier to implement, scale, and handle failures.. If both work for your application, this means the read-you-write does not bring any benefits to the application, but is harder to implement.
Reasoning:
- Minimized Latency: Read-Your-Writes (RYW) consistency often requires routing a client's requests to a specific "home" replica or waiting for a version to propagate to a local node before allowing a read. Pure eventual consistency allows a client to read from the absolute nearest/fastest replica, regardless of where the last write occurred.
- Higher Availability: Under RYW, if the specific replica holding the client's latest write becomes unreachable, the client might be blocked from reading their own data even if other replicas are healthy. Pure eventual consistency ensures the system remains available as long as any replica can be reached.
- Reduced Complexity: RYW requires the system to track session state or "causal tokens" to ensure the version order. Pure eventual consistency removes this metadata overhead, simplifying the load balancer and database logic.
- Problem 9 (medium)
You are tasked with optimizing a web service. The web server used to work fine, but since the web site became popular, the server’s performance deteriorated significantly. After profiling the server and studying the source code, you found that the old design uses a thread-per-request design.
-
What is a thread-per-request design? And why does it not scale well (under high number of requests)
It is a design that whenever a new request arrives, a new thread is created for it to run. It doesn’t scale well under high number of requests is because if there are millions of requests, there will be millions of threads concurrently running. The OS may spend most of their time on switching context which brings heavy overhead and spend barely time doing actual work.
-
Propose one optimization to the design that can improve the server’s performance. How the optimization you propose can help the server scale?
I will suggest using seda. This is better because it provides better modularity while still using threads per request. Each function has its own queue and number of threads, for which it can be tuned automatically based on the current workloads for that module. Each module is doing a specific type of work and distribute them to other modules after it is done. There is no overall queue that waits for a single task to finish, one task being blocked doesn’t affect others to proceed as there are many threads and after they are done they can move to another queue so that another request can come in to do the work for that module.
1. Thread-per-Request and its Scaling Issues
In a thread-per-request design, the server allocates a new, dedicated OS thread for every incoming connection. It does not scale well for two primary reasons:
- Resource Exhaustion: Each thread consumes a significant amount of memory for its stack. Under high concurrency (e.g., 100k requests), the server will run out of RAM long before the CPU is fully utilized.
- Context Switching Overhead: When the number of threads far exceeds the number of CPU cores, the OS spends more time saving and loading thread states (context switching) than executing actual application logic. This leads to "thrashing," where throughput drops to near zero.
2. Proposed Optimization: SEDA (Staged Event-Driven Architecture)
I propose implementing SEDA, which decomposes the request processing into a set of stages connected by explicit queues.
How SEDA Scales:
- Thread Pooling: Instead of one thread per request, each stage has a fixed-size thread pool. This limits the total number of threads in the system to a manageable level, preventing context-switching storms and memory exhaustion.
- Admission Control: Each stage can monitor its own queue length. If a stage becomes a bottleneck (e.g., slow disk I/O), it can trigger backpressure or drop requests early, preventing the entire server from collapsing.
- Decoupling: Because stages are separated by queues, a thread is only "busy" while it is doing actual work. Once it finishes its task for a stage, it puts the request in the next queue and immediately picks up a new task. This maximizes CPU utilization and allows different stages to be tuned independently based on the workload (e.g., more threads for I/O-heavy stages, fewer for CPU-heavy stages).
- Problem 10 (easy)
What are the two approaches for DNS lookup? State one advantage and one disadvantage for each one.
They are iterative and recursive.
The pros of iterative DNS lookup is that the DNS server doesn’t need to save the state of the request, which is less lightweight for them. If the record is not found in it, it just redirects the client to another server. The cons is that there may be multiple rounds and so several RTTs for the client and the latency would be higher as it may be far away from the DNS servers.
The DNS server does not fetch the answer itself; instead, if it doesn't have the record, it provides a referral (the IP address of the next DNS server in the hierarchy) to the client.
- Advantage (Statelessness): It reduces the load and resource consumption on high-level DNS servers (like Root and TLD servers). They do not have to maintain session state or wait for downstream responses, allowing them to handle massive volumes of traffic.
- Disadvantage (Client-side Latency): The client (resolver) must perform multiple "round trips" across the network to different servers. This increases the total time to resolve a name and puts the burden of work on the client.
The pros of recursive DNS lookup is that it saves time as the DNS servers usually locate together or closely, they can route the traffics more quickly due to shorter distance. The cons is that each DNS server needs to store the state of the request to track and return, which may be memory heavy and add up a lot of overhead.
The client sends a request to a DNS server (typically a local resolver), and that server takes full responsibility for finding the answer, querying other servers as needed until it returns the final IP to the client.
- Advantage (Efficiency via Caching): Since the recursive server handles many clients, it can cache results effectively. If a popular site is requested, the resolver can return the answer immediately from memory without any further network calls, significantly reducing latency.
- Disadvantage (Server Resource Exhaustion): The server must maintain the state of every pending request (storing the client's info while waiting for upstream answers). This makes the server vulnerable to resource exhaustion and memory pressure under high load or DDoS attacks.
- Problem 11 (medium)
How is request-routing done in Dynamo? Draw a diagram and explain:
-
How the storage space is partitioned and
The storage space in Dynamo is partitioned by putting the nodes randomly in a ring so that each node’s workload is relatively even, to avoid what’s happening in Chord that hashes the IP address on the ring as the positions as it may cause some nodes to handle many works than others. To compensate the fact that some nodes are strong and some nodes are weaker, a physical can have multiple virtual nodes, more for stronger nodes and fewer for weaker nodes.
-
How the system routes a get(key1) request to the node that stores key1.
There are two ways. The client can contact the load balancer that contacts any random nodes on the ring, and if that ring is not in the first N replicas of the preference list for key1, it will forward that request to the first node in the preference list to coordinate. The client can also use the libraries the contact the first node in the preference list directly, which reduces the work for forwarding.
Dynamo partitions its storage space using consistent hashing on a circular ring where physical nodes are mapped to multiple virtual nodes to ensure uniform load distribution and handle hardware heterogeneity. Request-routing is performed as a zero-hop DHT where every node maintains a local partition map to identify the "coordinator" (the first node in a key's preference list). Clients can reach this coordinator by routing through a load balancer (which may require an extra internal hop) or by using a partition-aware client library that hashes the key locally to send the request directly to the correct node, significantly reducing latency.
Initial Strategy (Strategy 1): Each physical node was assigned a fixed number of "tokens" (virtual nodes) at randomly chosen values within the 128-bit hash space. This meant the "size" of the partition between any two virtual nodes was random and variable.
Final Optimized Strategy (Strategy 3): To improve load balancing and bootstrapping, Amazon transitioned to a model where the hash space is divided into Q equally sized partitions. In this strategy, each node is assigned a set of these fixed partitions (Q/S tokens per node) rather than random points
-
Problem 12 (medium)
NFS was designed to have idempotent operations.
-
What are idempotent operations?
They are operations that no matter that how many times it has been executed, the result is unchanged, such that, the second time or more you executed the operation, the state of the system is unchanged. For example, read is an idempotent operation.
An idempotent operation is one that can be applied multiple times without changing the result beyond the initial application. In distributed systems, this means that if a client sends a request N times, the final state of the server is identical to a single successful execution. Examples include
READ,LOOKUP, andWRITEto a specific offset. -
What is the main advantage of idempotent operations in terms of fault tolerance?
The main advantage in terms of fault tolerance is that if a request fails, it can safely send the request again to the server without worrying about whether the operation has been executed. Even it has been executed, there is no negative effect as the state of the system won’t change after first execution.
Idempotency enables the use of at-least-once delivery semantics, which significantly simplifies error recovery. If a client experiences a timeout or network failure, it can safely retransmit the request indefinitely until it receives an acknowledgment. The server does not need to maintain complex state (like a request history table) to ensure it doesn't execute the same command twice, because duplicate executions do not harm the system state.
-
Delete operation can not be made idempotent. How NFS client handle delete operations that fail?
NFS client is responsible for checking the state of the system to see whether the file has been deleted successfully. If the file is gone, it means the server has executed the operation before it fails or it is just the ACK message lost. If the file is still there, send the request again.
If a delete function returns (error: file does not exist) consider this as a success ack.
-
-
Problem 13 (easy)
In Chord,
-
What is a finger table?
It is a table that allows the request to be forwarded to the correct node that is responsible for it half the distance every time it moves. it has m entries where m is the number of bits in the identifier. The i-th entry points to the first node that succeeds the node p at least 2^(i-1) on the cycle.
-
How is it filled?
Each entry with index i with the range {0,…,m-1}, the value is successor(p+2^(i-1)) % 2^m. After hashing the key of the request, it will send it to the node j where FT[j] ≤ hash(key) < FT[j+1].
-
What is the complexity of the lookup operation with and without the finger table?
With the finger table, the lookup operation takes O(log N) time. Without the finger table, it would be O(N). N is the number of server nodes.
-
-
Problem 14 (hard)
Assume total order multicast (TOM) is implemented a top the UDP protocol for higher efficiency. TOM assumes that messages are not reordered in the network. Modify the design of the total order multicast we studied in class to relax this assumption. Meaning, extend the design to support message reordering. Show what changes you will make to the messages and to the rules for forwarding messages to the application.
We will use 2PC here to make sure all application agree on the same order. Each sender will act as the coordinator. After it sends to message attached with “Prepared?” with timestamp to all other applications, the application will send either Yes or No. If the application sees the message and has a smaller timestamp compared with others, it will send a Yes, otherwise, it will send No to this sender but Yes to another message’s sender. If the sender receives any No, it will abort the transaction and try again later.
- Sender sends message to sequencer
- Sequencer:
- assigns global sequence number
- multicasts
(msg, seq)to everyone
- Problem 15 (hard)
Design a coordinator-less distributed 2PC system. In this system one node receives the client request and forwards it to all the participants. After this step, the participants decide to commit or abort a transaction without a central coordinator.
- Presents the steps for reaching a decision (commit/abort) a new transaction?
- The client sends request to all participants.
- The participant decides whether to commit local, and broadcast the decision to all other participants.
- The participant receives the decision from all other participants ~~and ack back to let them know “I have received your decision”~~. If all saying commit, then commit; If any of them saying abort, then abort the transaction.
- If the decision from a specific participant is not received, after timeout, send the request to it again. After several attempts, if still cannot receive, send messages to all other participants asking if they receive the decisions from it. If one participant receives the final decision, share it.
-
Is your protocol a blocking protocol? Explain why?
It depends on how long we want to wait for the failed node to respond. If the participant keeps sending request to the failed node until it acks back if no one receives the final decision from it, it may be blocking forever. If no one receives the final decision from the failed participant after a time period, all other participants can decide to abort.
Yes, it is still a blocking protocol. If all participants who have received the full set of votes crash, or if a participant crashes after voting "Commit" but before hearing the final result, the remaining "uncertain" nodes cannot move forward. A transaction is blocked if the only nodes that know the outcome are unreachable. Removing the coordinator just spreads this risk; it doesn't eliminate it.
Imagine 3 nodes: A, B, and C.
- Node A decides to commit. It starts sending its
VOTE_COMMITto B and C. - Node B receives the vote.
- Node A crashes before the packet reaches Node C.
- Node B now has all the votes (it knows its own, A's, and C's). Node B commits.
- Node B crashes immediately after committing.
The Resulting Block
Now look at Node C (the only one left alive):
- Node C has its own vote.
- Node C might have Node B’s vote.
- Node C NEVER received Node A’s vote.
Node C is now stuck. It cannot commit because it doesn't know if A voted to commit or abort. It cannot abort because B might have already committed (which it did). Because the only nodes that know what A did (A and B) are both dead, Node C is blocked.
- Node A decides to commit. It starts sending its
-
Problem 16 (medium)
-
Explain how reference listing is used for garbage collection in RMI?
So skeleton keeps a reference listing for all remote objects it holds in RMI. Every node that has the remote object will be in this list, with a timer. After the timer expire (such that the node didn’t renew its lease), it will remove that node from the list. If the list is empty, it will clean up and do garbage collections on that remote object created.
The server-side RMI runtime maintains a referenced list (or "dirty set") for every exported remote object. This list contains the unique identifiers of all client virtual machines (JVMs) that currently hold a remote reference (stub) to that object.
- Cleanup Rule: The server will only perform local garbage collection on a remote object once its reference list is empty.
- What role do leases play in this approach?
All nodes that want to keep the remote object must lease from the skeleton. They have to renew the lease periodically in order to keep the object on local.
Leases are used to prevent distributed memory leaks caused by client crashes or network partitions.
- Fault Tolerance: Since a crashed client cannot send a
clean()call, the server grants references for a limited Lease Period. - Renewal: The client must periodically renew the lease by sending another
dirty()call before the timer expires. - Expiration: If a lease expires without renewal, the server assumes the client is unreachable and removes it from the reference list, allowing the object to be collected if no other clients are active.
- Problem 17 (medium)
- Cleanup Rule: The server will only perform local garbage collection on a remote object once its reference list is empty.
Complex system designers aim to design systems that have low mean time to repair (MTTR). Meaning if a failure happens it will be quick to detect the failure, quick to diagnose the problem, and quick to fix. To achieve this goal, practitioner, advise to design the system into modules that have limited shared state between them. List two other properties of this modular design that will reduce the time to detect a failure.
Two additional properties are: (1) well-defined module interfaces, which allow failures to be localized and detected through incorrect inputs/outputs, and (2) strong observability mechanisms such as logging, metrics, and health checks, which enable rapid detection of abnormal behavior within individual modules.
When a module is strongly encapsulated, a failure is less likely to "leak" into other modules in subtle, quiet ways. Instead, the failure tends to hit the interface boundary and trigger an immediate, observable error (like an exception or an invalid return type), making it much faster to pinpoint which module is broken.
If a module is designed to provide high-level health signals, monitoring systems can detect a "silent hang" or a "gray failure" immediately. Without this, you might have to wait for a total system crash before you realize a specific module has stopped processing requests.
-
-
Problem 18 (easy)
List two main differences between TCP and UDP.
- TCP requires 3-way handshaking before connection but UDP does not need to.
- TCP guarantees in-order delivery but UDP is “best-effort” model that doesn’t even guarantee delivery.
- Problem 19 (medium)
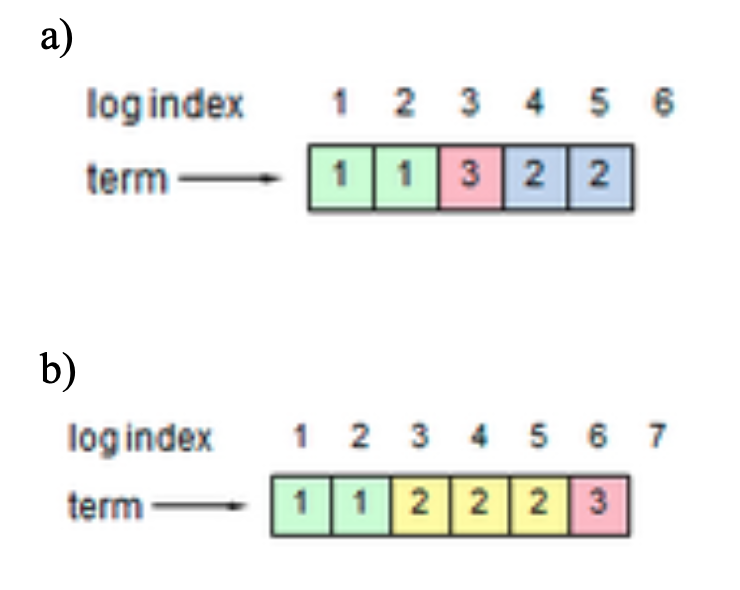
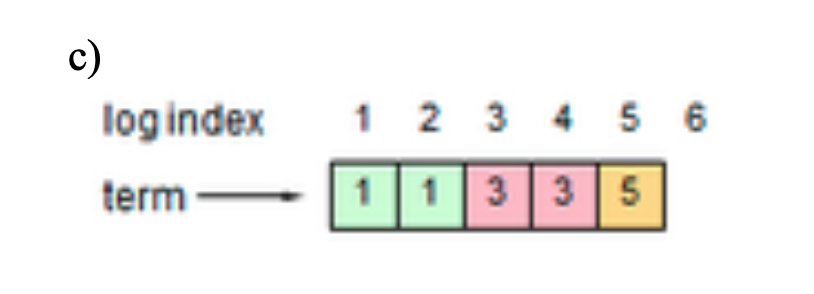
Each figure below shows a possible log configuration for a Raft server (the contents of log entries are not shown; just their indexes and terms). Considering each log in isolation, could that log configuration occur in a proper implementation of Raft? If the answer is "no," explain why not.
- No, the term must be non-decreasing in the log.
- Yes
- Yes
-
Problem 20 (hard)
Extend the Central Server Algorithm design for mutual exclusion to be able to tolerate two failures:
-
Failure of a node that is holding the lock
The node holding the lock must send heartbeat periodically while holding the lock to let the coordinator know it is still alive and doing the work.
If the coordinator stops receiving heartbeats from the lock holder, it assumes the node has crashed. The coordinator revokes the lock and grants it to the next node in the wait queue.
-
Failure of the coordinator. Present your solution for detecting the coordinator failure and how the remaining nodes can continue to after a coordinator failure.
If any node detects no response from the coordinator when sending it request, it can assume the coordinator has failed. Then, it will begin its own election algorithm. For example, we can use bully algorithm to let the node with the highest process id to be the new leader/coordinator.
To continue after a coordinator failure, the system must recover the "Lock State" (who has the lock and who is waiting).
Reconstruction of State: This is the critical step. The new coordinator has two options:
- Passive Waiting: The new coordinator broadcasts a "Who has the lock?" message. The current holder (if alive) responds with its lease info. Other nodes re-submit their
REQUESTto rebuild the queue. - Replicated State: (Advanced) The original coordinator could have used a Consensus protocol (like Raft) to replicate the lock queue to a backup. The new coordinator simply takes over the replicated state.
- Problem 21 (hard)
- Passive Waiting: The new coordinator broadcasts a "Who has the lock?" message. The current holder (if alive) responds with its lease info. Other nodes re-submit their
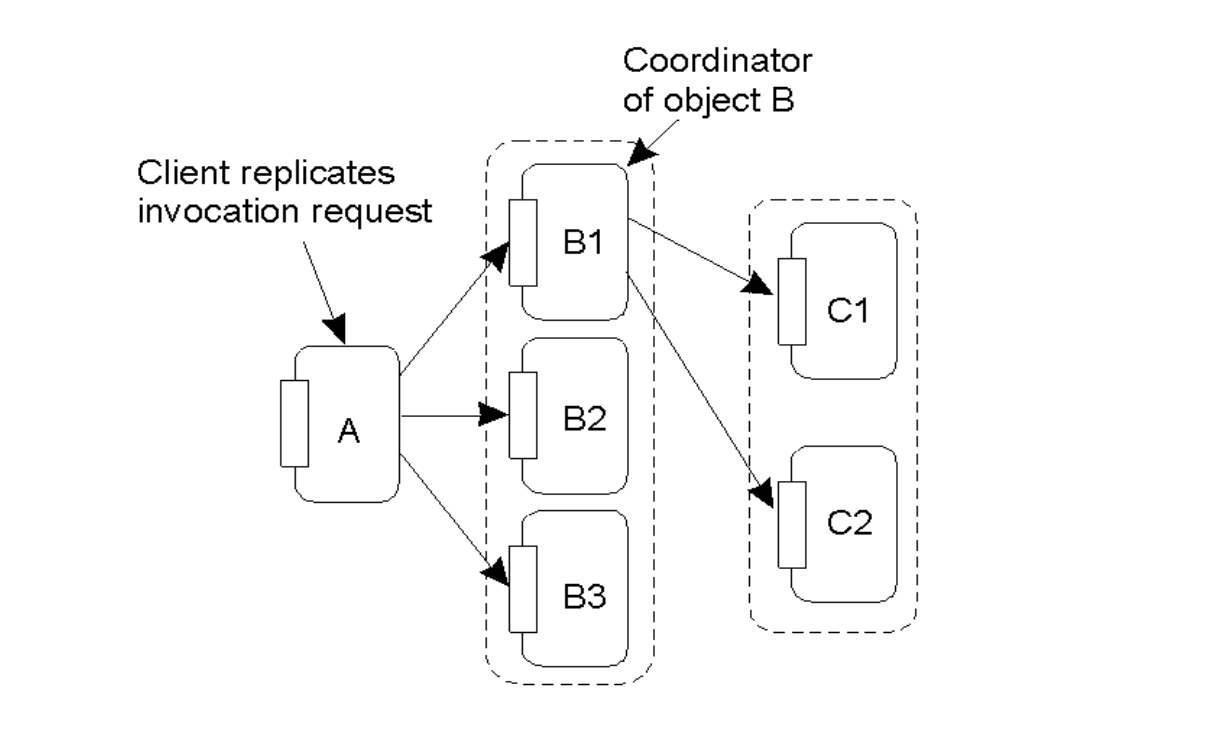
The figure below shows a replicated remote object B that has a coordinator. Design a garbage collection approach for such a system that uses replicated objects shown in this figure. Remember the copies of the object B (which are B1, B2, and B3) are on different machines. Your solution should handle network failure between the client and all or some of the replicas, and also network failures between replicas.
When client requests the remote object B, it will send to the coordinator of object B first, that is B1. Then B1 will use consensus algorithm like Raft to make sure most of the nodes will update their preference lists accordingly, so that we can make sure the state of the preference list is saved in majority of the machine so it never gets lost even when the coordinator failed. If the coordinator failed, it is fine as Raft will make sure there will a leader with the most completed reference list. When client reaches the original coordinator but failed, it can reach any other replicas that could direct the request to the new leader/coordinator. By all means, we use Raft to make sure the state of preference lists are consistent between replicas. Even if there is network partition, only the majority group can continue the operations (and elect new leader if needed) and the minority group is basically unavailable.
To implement a garbage collection approach for replicated object B, the system should treat the Reference List as a Replicated State Machine managed by a consensus protocol like Raft. The current coordinator (B1) acts as the Raft leader, receiving all
dirty()andclean()requests from the client and replicating them to a majority of the followers (B2, B3) before committing them to the global reference list. This ensures that even if the coordinator or a specific replica fails, the state of who holds a lease is never lost, as the newly elected leader will have the most up-to-date log. To handle network failures, the client uses a replicated stub to redirect lease renewals to any available replica, which then forwards the request to the current leader.The system remains safe during network partitions because only the majority partition can commit lease renewals or make the final decision to garbage collect the object. If the client is partitioned away and cannot reach the majority to renew its lease, the lease will eventually expire across the majority replicas, allowing them to safely collect the object once the reference list is empty. This prevents "Split Brain" scenarios where a minority group might keep an object alive while the majority deletes it. By using lease-based heartbeats integrated into the consensus log, the system maintains high availability and consistency without requiring a single, non-failing central point of control. Only when the Leader confirms that no active leases exist across the majority can it broadcast a final "Delete Object" command to all replicas.
-