Map-Reduce¶
Large-Scale Data Processing¶
MapReduce Stack¶
MapReduce sits at the top of Google's distributed computing stack, abstracting the complexities of the underlying infrastructure.
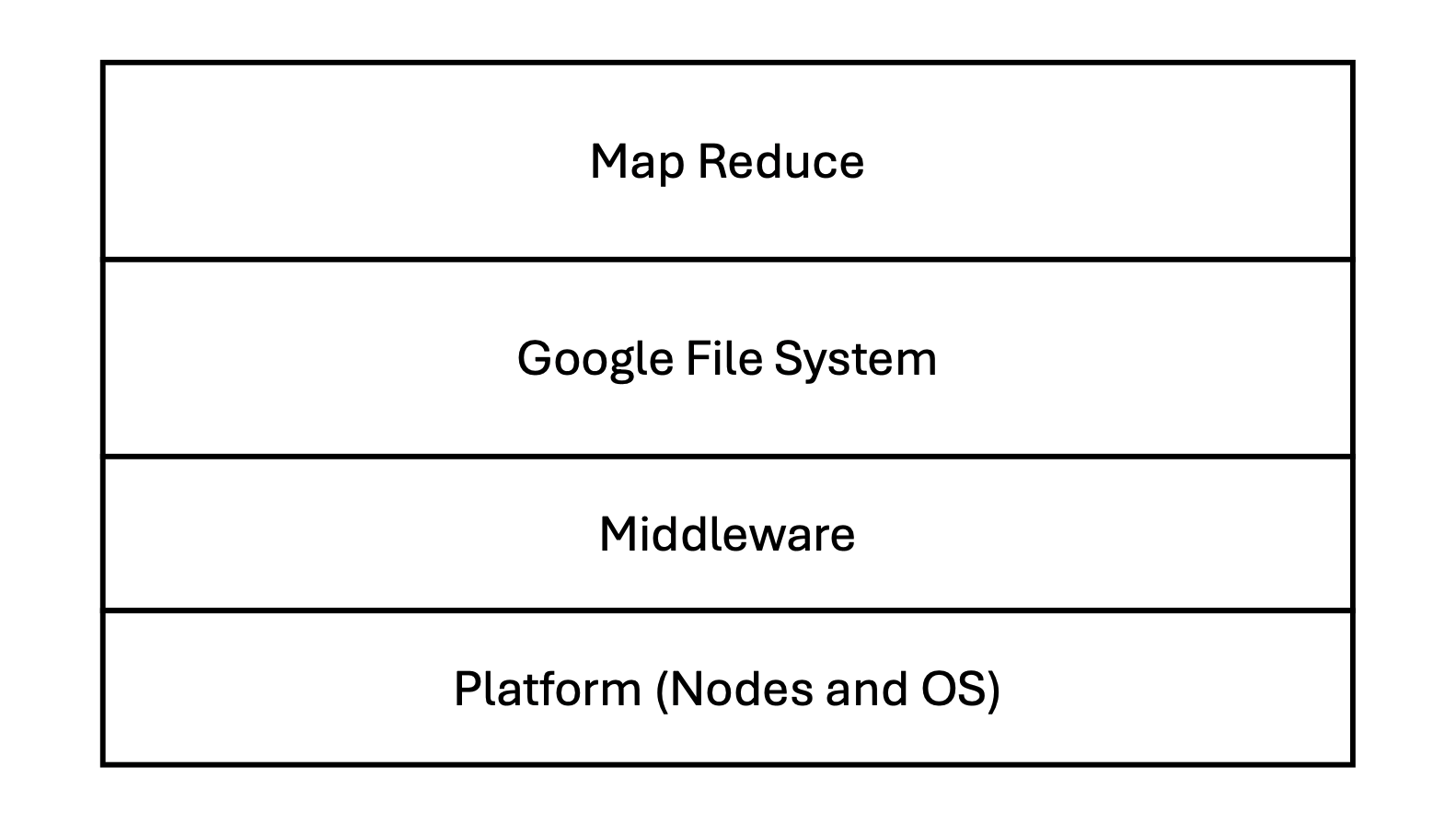
- MapReduce: The programming model and execution framework.
- Google File System (GFS): The distributed storage layer providing data to MapReduce.
- Middleware: Communication and management layers.
- Platform: The physical nodes and Operating System.
Core Goals and Concepts¶
The primary goal of MapReduce is to enable data processing at scale (e.g., web search indexing) by efficiently utilizing thousands of machines while automatically handling hardware failures.
Key Ideas¶
- Divide and Conquer: Work is "chopped" into many small pieces.
- Atomic Operations: Each piece is processed independently.
- Fault Tolerance: If a specific task fails, the framework simply restarts it on a different worker.
- Abstraction: Complexity like scheduling, data distribution, and failure handling is hidden from the developer.
Programming Model¶
The model is based on two user-defined functions: Map and Reduce.
The Map Function¶
Processes a key/value pair to generate a set of intermediate key/value pairs.
Map(K, V)
# ... process input ...
Emit(k', v')
The Reduce Function¶
Combines all intermediate values associated with the same intermediate key.
Reduce(k', iterator(v'))
# ... process list of values ...
Emit(result)
Example: Word Frequency¶
A classic use case is counting how many times each word appears in a massive collection of documents.
Map(k, v):
# k: document name; v: document content
foreach word in v:
Emit(word, 1)
Reduce(k', iterator):
# k': a specific word; iterator: a list of counts (1, 1, 1...)
result = 0
foreach v in iterator:
result += v
Emit(k', result)
System Design and Execution Steps¶
The execution is managed by a Master node that assigns tasks to a pool of Worker nodes.
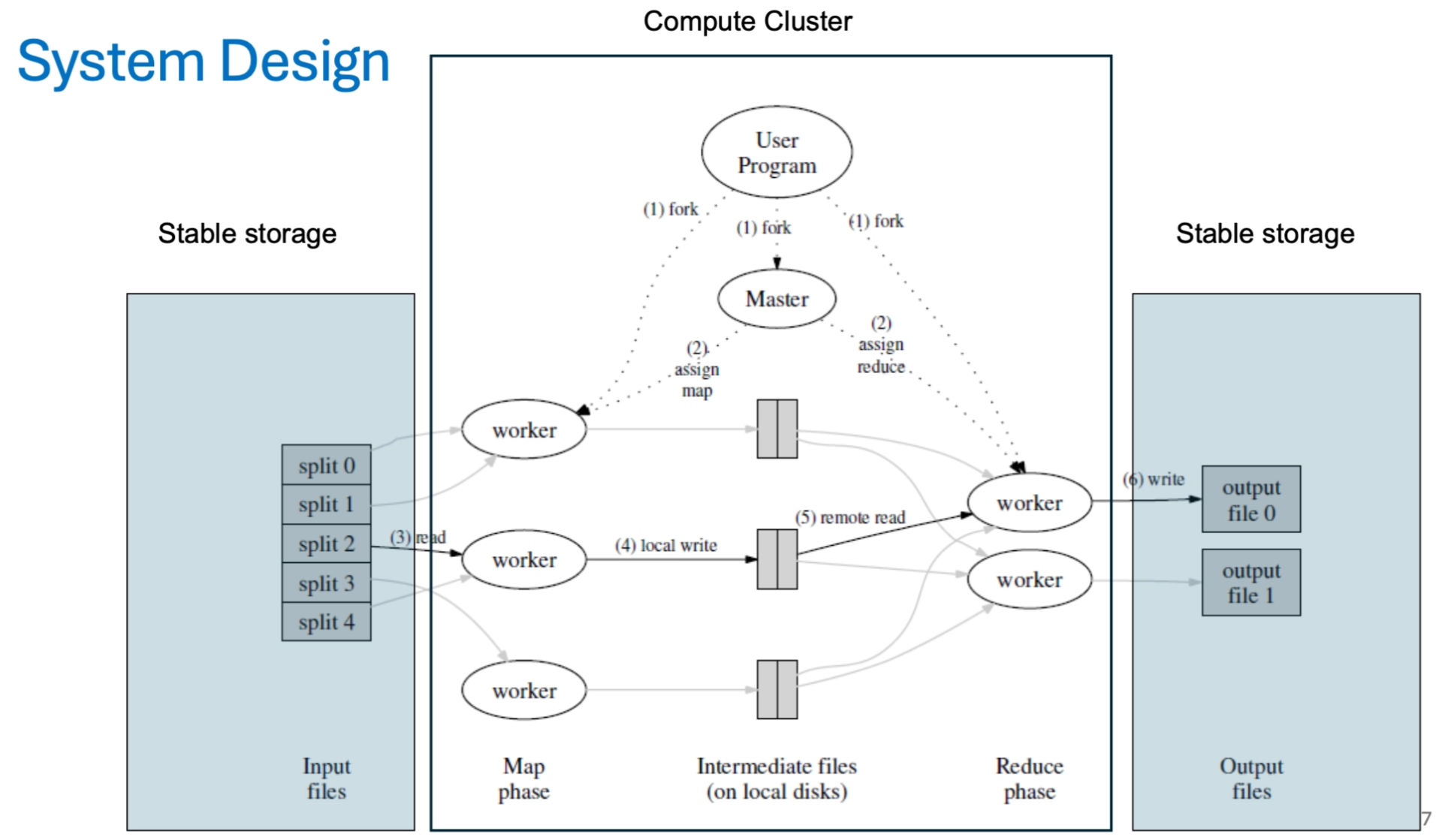
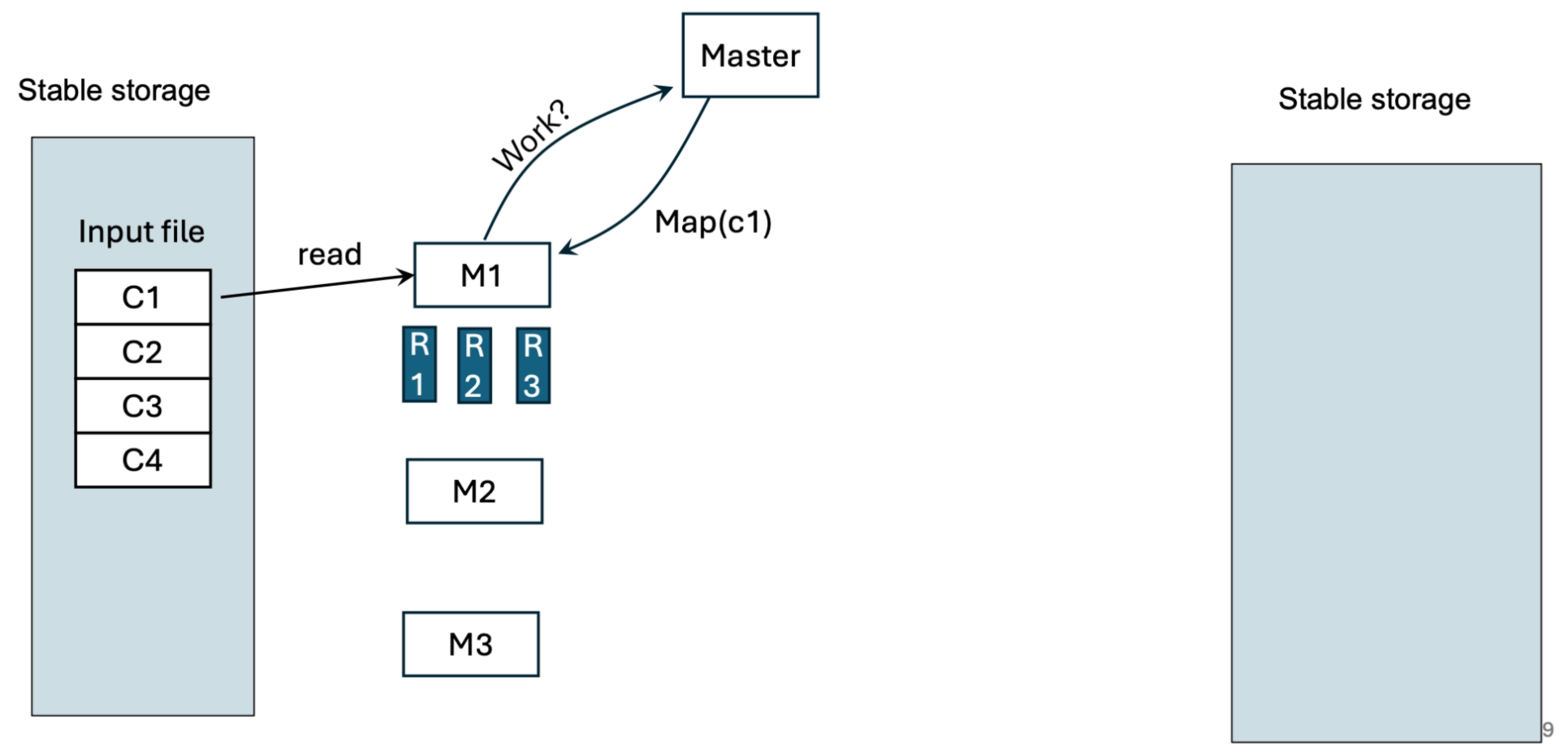
Phase 1: The Mapping Step¶
- Job Submission: The client specifies the number of Map (\(M\)) and Reduce (\(R\)) tasks.
- # of mappers ≈ # of input splits (blocks)
- Users typically do NOT manually specify number of mappers
- Splitting: The input file (stored in GFS) is split into \(M\) pieces (typically 16-64 MB).
- Assignment: The Master picks idle workers and assigns them Map tasks.
- Mapping: Mappers read their assigned input split, process it, and buffer the results in memory.
- Partitioning: Periodically, the buffered data is written to the mapper's local disk, partitioned into \(R\) regions (one for each reducer).
- Each Map worker writes its intermediate data to its local disk. It partitions this data by applying a hash function (e.g.,
hash(key) mod R) to the keys.
- Each Map worker writes its intermediate data to its local disk. It partitions this data by applying a hash function (e.g.,
The number of intermediate files (partitions) \(=\) the number of reducers, such that reducer \(i\) will get the partition \(i\), etc..
The Assignment Hierarchy¶
When a Mapper needs to be assigned to a specific "Input Split" (a chunk of your file), the scheduler looks for a worker in this specific order of preference:
1. Data-Local (The Gold Standard)
The scheduler tries to find a worker node that is already storing the physical block of data on its local disk. If that worker is idle, it gets the task. No data is moved over the network.
2. Rack-Local
If the data-local node is 100% busy, the scheduler looks for a worker on the same server rack. Since machines on the same rack are connected by a high-speed local switch, transferring the data is still relatively fast.
3. Off-Switch (The Last Resort)
If the entire rack is busy, the scheduler assigns the task to a worker in a different rack. This is the least efficient method because the data must travel through the main data center switches.
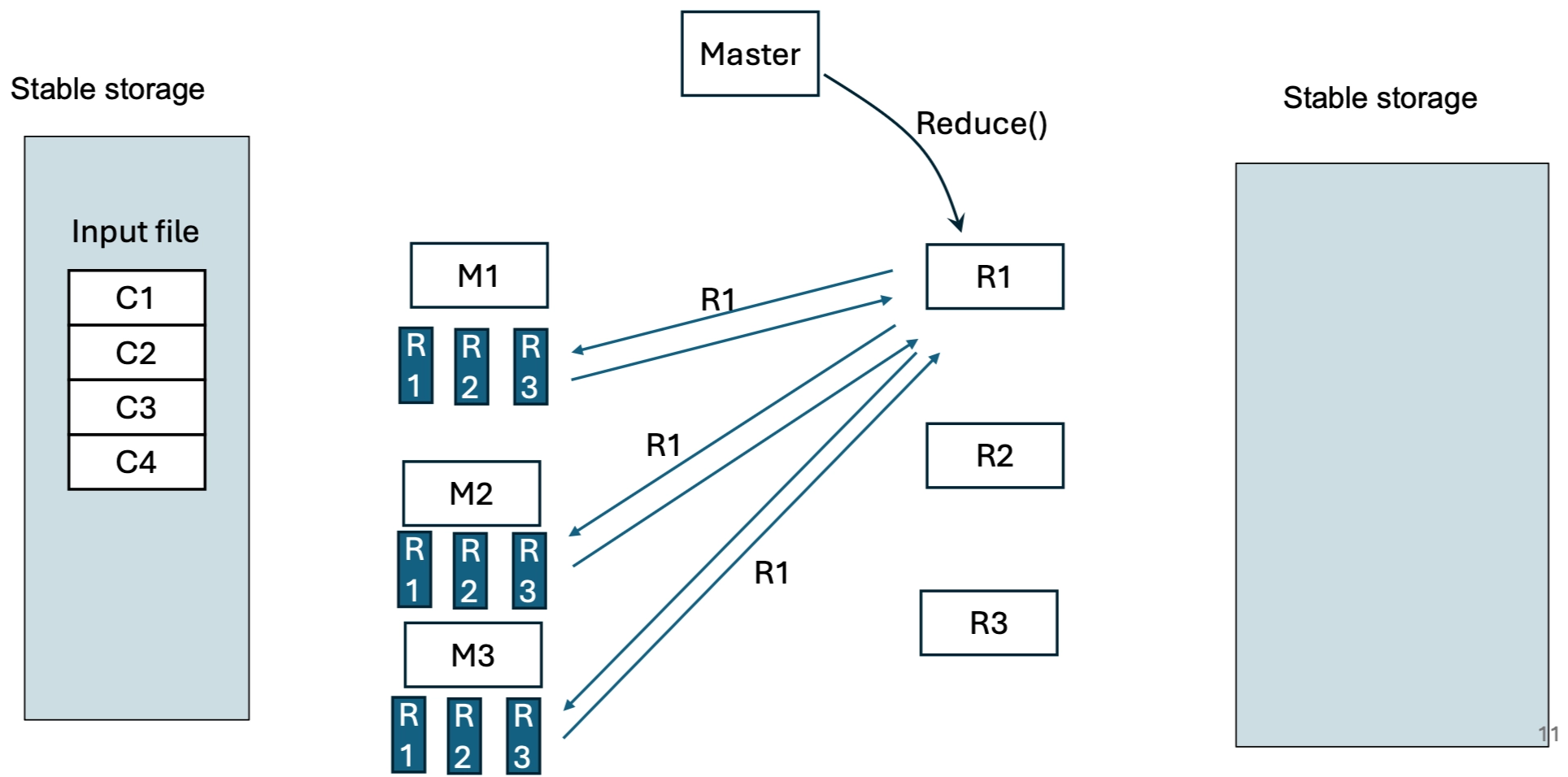
Phase 2: The Reduce Step¶
- Notification: When a mapper finishes, it informs the Master of the locations of its \(R\) intermediate files.
- Data Shuffle: The Master passes these locations (pointers) to the Reducers. Reducers use Remote Procedure Calls (RPCs) to read their specific partition from every mapper's local disk.
- Sorting: The Reducer sorts the intermediate data by key so that all occurrences of the same key are grouped together.
- Reducing: The Reducer passes each unique key and its corresponding list of values (
<key, list of values>) to the user'sReducefunction. - Output: The final results are written to \(R\) separate output files (one per reducer) in the shared Google File System.
Fault Tolerance¶
In a large-scale cluster, the probability of at least one node failing is high. MapReduce is designed to handle these failures at different levels.
Master Failure¶
- Action: If the Master node fails, the entire MapReduce job is typically aborted and restarted ("repeat the whole thing").
Worker Failure¶
- Detection: The Master periodically pings every worker to check its status.
- Mapper Failure:
- During Execution: If a worker fails while mapping, the task is re-executed by a different worker.
- Completed Task: Even if a Map task was completed, it must be re-executed if the worker node fails. This is because mappers store their intermediate output on their local disks, which become inaccessible upon failure. Reducers are then notified of the location.
- Reducer Failure:
- During Execution: The task is re-executed on a different worker.
- Completed Task: If the Reducer has already completed and committed its output to the Google File System (GFS), no re-execution is necessary because GFS provides global persistence.
Challenges¶
How do you handle double mapper execution?
MapReduce ensures that only one "successful" execution is recorded. If two workers execute the same map task (e.g., due to a slow worker being mistaken for a failed one), the Master only recognizes the first completion and informs the reducers of that specific intermediate file location.
How do you handle double reducer execution?
Reducers rely on the atomic rename operations provided by GFS. Each reducer task writes to a temporary private file. Only when the task is fully complete does it rename the file to the final output name. If two reducers finish the same task, the underlying file system ensures only one rename succeeds, maintaining data integrity.
Stragglers¶
A "straggler" is a machine that takes an unusually long time to complete one of the last few map or reduce tasks in a job, often due to bad disks, CPU contention, or network issues.
- The Impact: The entire job is only as fast as its slowest task.
- The Solution: When a processing step is close to finishing (e.g., only 5% of tasks remain), the Master schedules backup tasks for all remaining active tasks.
- Mechanism: The "first to finish wins." Once either the primary or the backup task completes, the Master marks the task as done and ignores the other one.
Locality¶
Network bandwidth is often a bottleneck in large clusters. To conserve it, MapReduce leverages the fact that GFS is deployed on the same nodes as the MapReduce workers.
- Data Locality: The Master attempts to schedule Map tasks on nodes that already store a replica of the input data split.
- Input data split read means a map task reads its assigned chunk (split) of the data.
- Don’t send data over the network when reading a split — run computation where the data is
- Fallthrough: If that node is busy, it tries a node "near" that data (e.g., on the same network switch) to avoid unnecessary cross-cluster network transfers.
System Optimizations¶
To further improve performance and robustness, several optimizations are available:
- Partition Function: Users can specify how data is distributed across reducers (e.g., using
hash(key) mod R). - Combiners: A "mini-reducer" that runs on the Mapper node. It partially merges data before it is sent over the network, significantly reducing the amount of data transferred for operations like word counts.
- I/O Reader/Writer: Customizable interfaces to support different file formats.
- Skipping Bad Records: If certain records cause the worker to crash (e.g., due to a bug in the user code), the framework can detect this and skip those specific records to ensure the rest of the job completes.