Mutual Exclusion¶
Mutual Exclusion in Distributed Systems¶
The Mutual Exclusion Problem¶
The Concept
- Systems involving multiple processes often use Critical Regions to protect shared data structures.
- Goal: Ensure only one process uses the shared resource at a time.
- Challenge: Unlike single-processor systems (which use semaphores/monitors), distributed systems lack Shared Memory, so they must achieve this via message passing.
Requirements To be valid, any solution must satisfy four conditions:
- Safety: At most one process may execute in the critical section at a time.
- Liveness: Requests to enter and exit eventually succeed (no deadlocks).
- Ordering: If request A happened-before request B (\(A \rightarrow B\)), then A is granted entry before B.
- No Starvation: No process waits forever.
Centralized Algorithm (Coordinator)¶
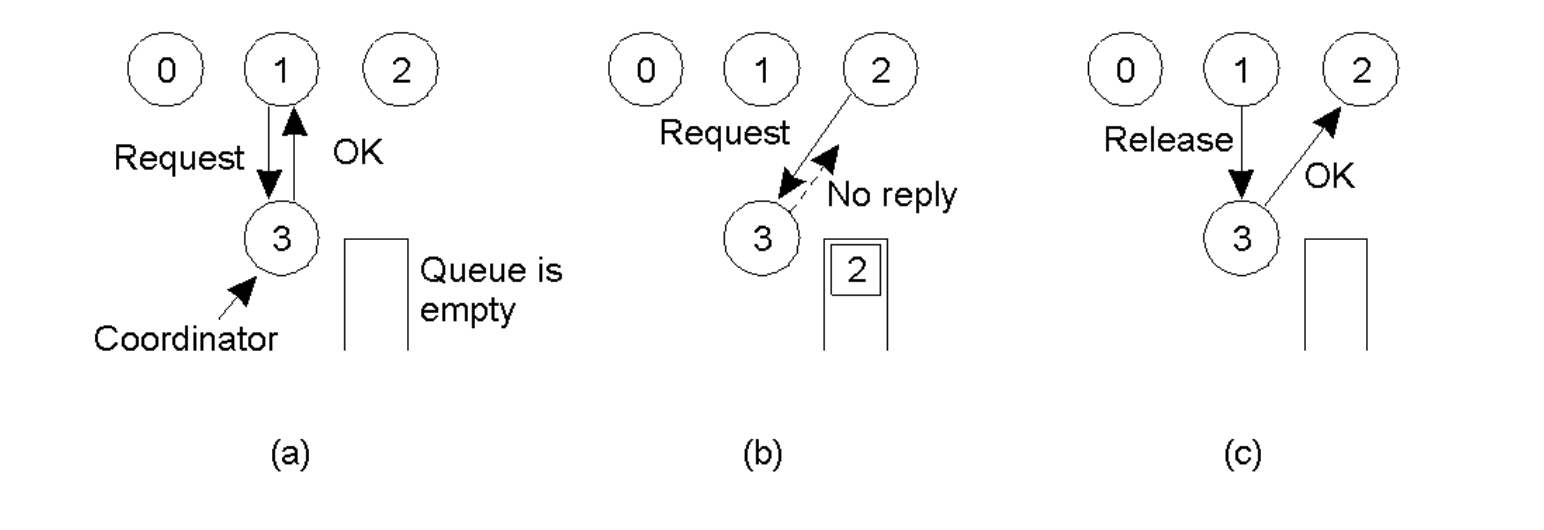
Mechanism
- One process is elected as the Coordinator.
- Request: Process 1 sends a
Requestmessage to the coordinator. - Grant:
- If the region is free, the Coordinator sends
OK(Permission Granted). - If the region is busy, the Coordinator does not reply and queues the request.
- If the region is free, the Coordinator sends
- Release: When done, Process 1 sends
Release. The Coordinator then pulls the next request from the queue and sendsOKto that process.
Analysis
- Pros: Simple, Fair (FIFO), No starvation, Easy to implement.
- Cons: The Coordinator is a Single Point of Failure and performance bottleneck. If it crashes, waiting processes cannot distinguish "dead coordinator" from "permission denied" (blocking).
- Cost: 2 messages before entering; 3 messages per entry/exit (Request, Grant, Release).
Distributed Algorithm (Ricart-Agrawala)¶
Mechanism
- Based on Total Ordering of events (Lamport Timestamps).
- Lamport timestamps are used to create a consistent global ordering of requests, so all processes can agree who should enter the critical section next.
- Request: A process broadcasts a message
{name_of_critical_region, process_id, current_timestamp}to all other processes. - Decision Logic (Upon receiving a request):
- If receiver is not in critical region (CR) and doesn't want to enter \(\rightarrow\) Send
OKimmediately. - If receiver is in CR \(\rightarrow\) Do not reply, queue the request.
- If receiver wants to enter CR \(\rightarrow\) Compare timestamps with the one contained in the message it has sent everyone. If the incoming message is "older" (lower timestamp), send
OK. If "newer," queue it.
- If receiver is not in critical region (CR) and doesn't want to enter \(\rightarrow\) Send
- Entry Rule: You enter only after receiving
OKfrom everyone.
Analysis
- Cons: Replaces single point of failure with \(n\) points of failure. If any process crashes and stays silent, the system deadlocks. It is slower and more complex than the centralized approach.
- Cost: \(2(n-1)\) messages before entering as well; \(2(n-1)\) messages per entry/exit, where \(n\) is the number of nodes.
In a Centralized system, only the Coordinator needs to know who is online. In this Distributed system, everyone must know everything. If any single process has a wrong list, the whole system can break.
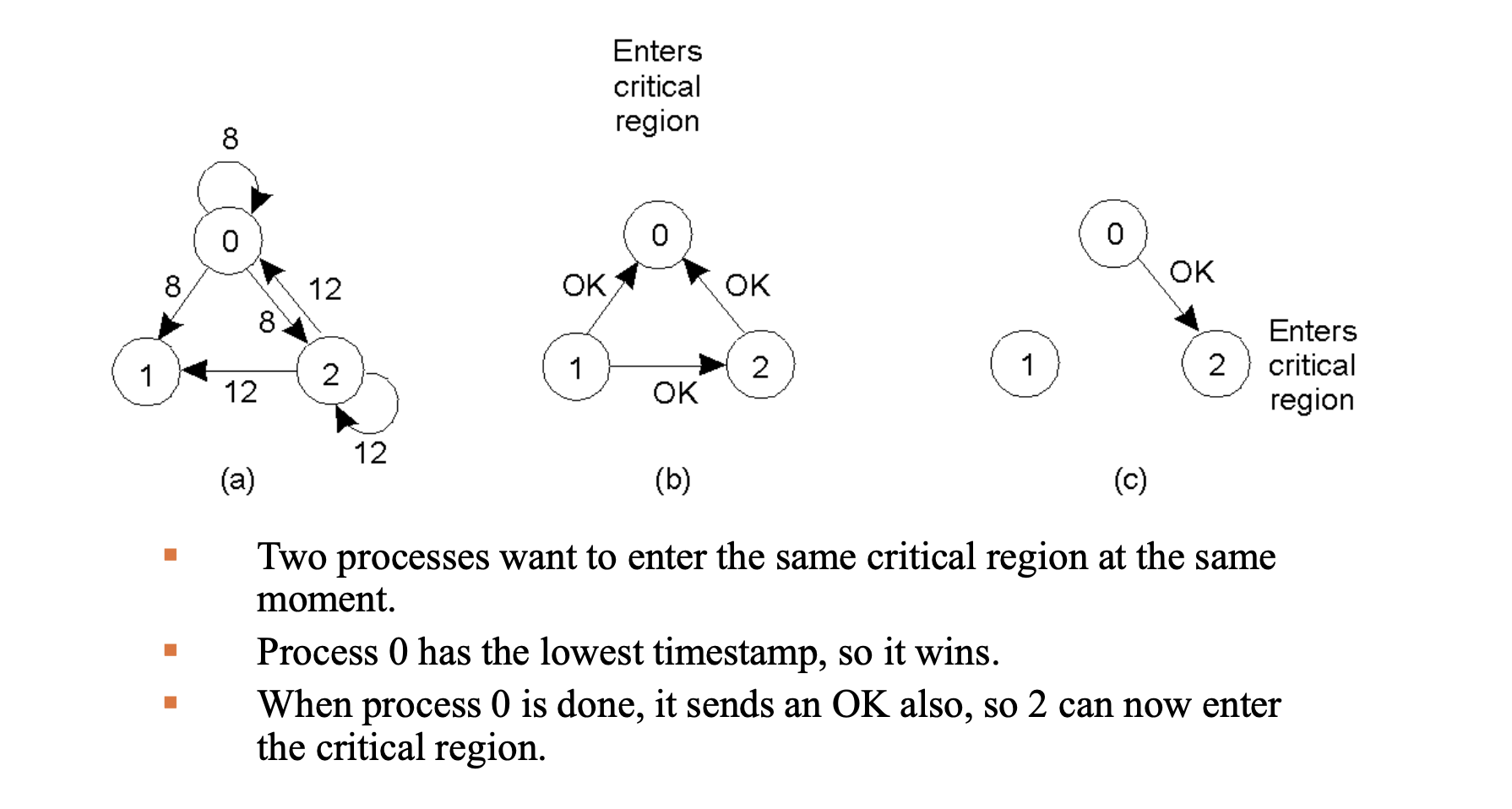
The node sending still sends a “message” to itself so it can compare, but that message is within the process and not going over the internet, so we don’t count it in the cost.
Token Ring Algorithm¶
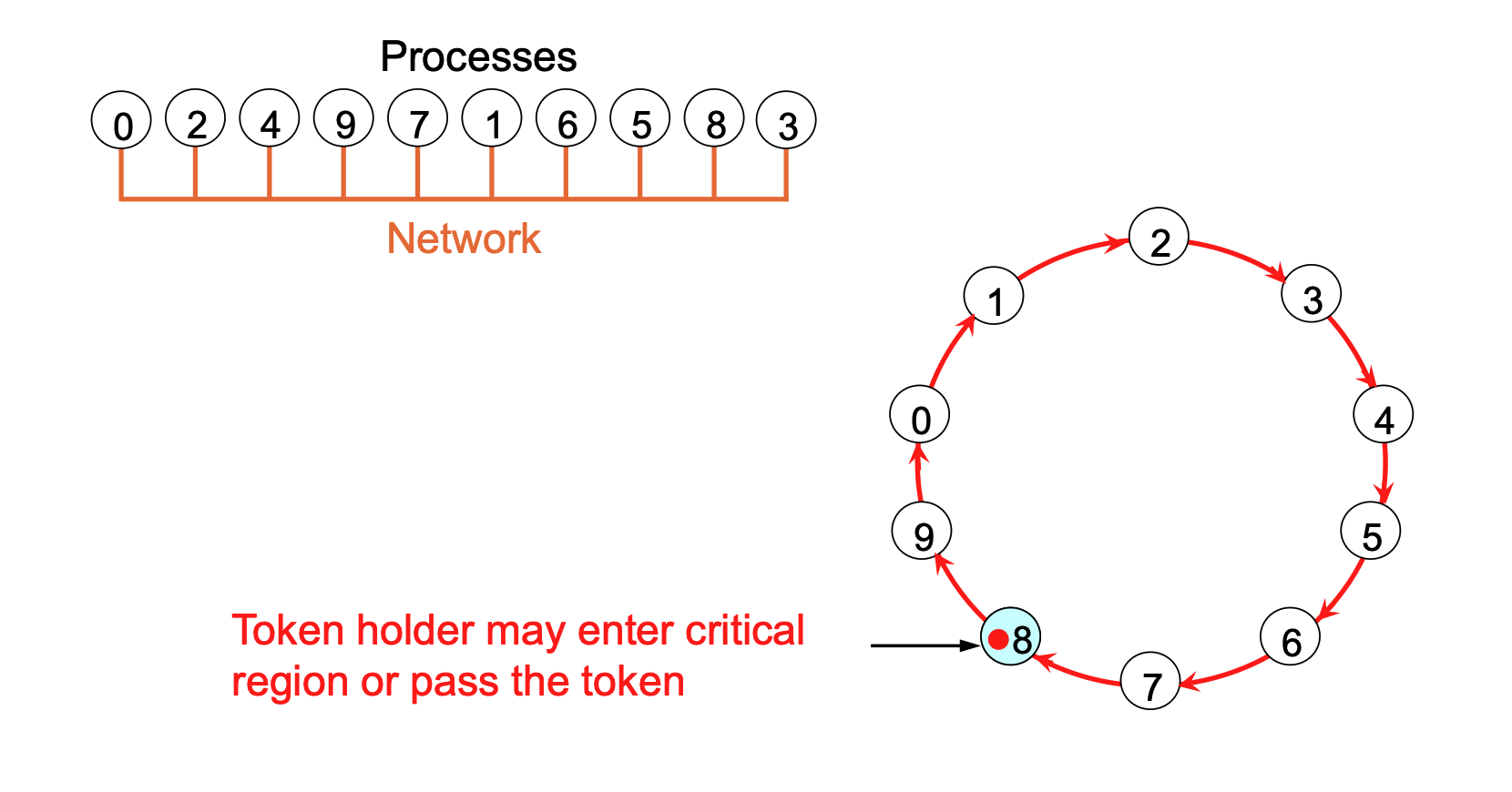
Mechanism
- Processes are logically organized in a ring structure.
- A Token circulates around the ring.
- Rules:
- Only the process holding the token can enter the critical region.
- If the holder doesn't need to enter, it passes the token to its neighbor immediately.
- If it does enter, it holds the token until it exits the region, then passes it on.
Analysis
- Pros: Guarantees mutual exclusion and prevents starvation.
- Cons:
- Lost Token: Detecting a lost token is difficult because the wait time is unbounded (you don't know if the token is lost or just being used).
- Process Crash: A crash breaks the ring topology, requiring recovery steps.
- If we require a process receiving the token to acknowledge receipt. A dead process is detected when its neighbor tries to give the token and fails. Dead process is then removed and the token handed to the next process down the line.
- Cost: Variable. Messages per entry can range from 1 to \(\infty\) (token passes constantly even if idle).
The delay before entering a critical region fluctuates between 0 messages (if the node already holds the token) and \(n−1\) messages (if the token just left and must traverse the entire ring to return). Additionally, the message cost per entry is considered to range from 1 to \(\infty\) because the token must constantly circulate to maintain the network topology; if the system runs for a long time without anyone entering the critical region, it generates an infinite number of maintenance messages for zero useful work.
- Why at least 1 message cost? The "1 message" minimum refers to the transfer of responsibility required to complete an entry/exit cycle. To exit the process and allow the system to continue, you must send that 1 message to your neighbor.
Comparison of Algorithms¶
Summary of performance and failure modes:
| Algorithm | Messages per Entry/Exit | Delay before entry (Msg times) | Problems |
|---|---|---|---|
| Centralized | 3 | 2 | Coordinator crash |
| Distributed | \(2(n-1)\) | \(2(n-1)\) | Crash of any process |
| Token Ring | 1 to \(\infty\) | 0 to \(n-1\) | Lost token, process crash |
1. Messages per Entry/Exit = "The Bill" (Total Cost)
This counts every single message generated by the entire system to handle one process entering and leaving the critical region.
- It includes the Request (asking to enter).
- It includes the Permission (getting the OK).
- It ALSO includes the Release (telling everyone you are done).
- It ALSO includes background overhead (like the Token circulating forever).
2. Delay before Entry = "The Wait" (Latency)
This measures time (specifically, how many sequential message steps you must wait) before you are allowed to start working.
- It ONLY counts the steps leading up to your entry (Request + Permission).
- It does NOT count the "Release" message (because that happens after you are already done).
Example: The Centralized Algorithm
- Delay (2): You send
Request(1) → You receiveGrant(2). You start working. Wait time: 2 steps. - Total Messages (3):
Request(1) +Grant(1) +Release(1). Total bill: 3 messages.
Conclusion: The messages that cause the delay (Requests/Grants) ARE part of the total message count. However, the total count is usually higher because it also includes the cleanup messages sent after you finish.
Election Algorithms¶
The Election Problem¶
Why it is needed
- Many distributed algorithms (like centralized mutual exclusion) rely on a single process acting as a coordinator.
- If the coordinator crashes, the system must agree on a replacement to take over the special responsibilities.
- Goal: It usually does not matter which specific process takes over, as long as exactly one is chosen. The standard approach is to elect the process with the highest process number (e.g., network address).
Assumptions
- Every process has a unique ID number.
- Every process knows the ID number of every other process.
- Processes do not know which processes are currently online (up) or crashed (down).
The Bully Algorithm¶
Mechanism
- Trigger: When a process (\(P\)) notices the coordinator is not responding, it initiates an election.
- The Process:
- \(P\) sends an
ELECTIONmessage to all processes with higher ID numbers. - If no one responds: \(P\) wins the election and becomes the coordinator.
- If a higher process responds: It sends an
OKback to \(P\). \(P\) then gives up and waits. The higher process takes over the election.
- \(P\) sends an
- Victory: Eventually, all processes give up except the one with the highest ID. It sends a
COORDINATORmessage to everyone declaring victory.- In the Bully Algorithm, the election process is essentially a chain of higher-ranking processes "pulling rank" on lower ones. When a process receives an election request from a colleague with a lower ID, it immediately asserts its dominance by sending an OK message—effectively telling the lower node to stop because "I am bigger than you, I will take over". This receiver then initiates its own election to check if it is the highest, continuing the chain until the process with the absolute highest ID silences everyone else and declares itself the coordinator. This logic applies even when a crashed node recovers, which holds an election when it comes back; if it has a higher ID than the current leader, it immediately bullies its way back into power, ensuring the active process with the highest number is always the coordinator.
Any process that comes back from a crash—or notices a failure—must immediately initiate an election to find out who the current leader is.
The "Bully" Rule
- If a crashed process recovers, it holds an election immediately.
- If it has a higher ID than the current coordinator, it will win and take over the job. Hence, "The biggest bully in town always wins".
- The Recovery: A process with a high ID (let's say Process 7) wakes up after a crash. It doesn't care that Process 6 is currently running the show peacefully.
- The Challenge: Process 7 immediately holds an election by sending messages to everyone with a higher ID than itself.
- The Takeover: Since Process 7 is the highest (nobody higher responds), it declares itself the winner and sends a
COORDINATORmessage to everyone—including the old coordinator (Process 6). - The Result: Process 6 is effectively demoted immediately, and Process 7 takes over the job.
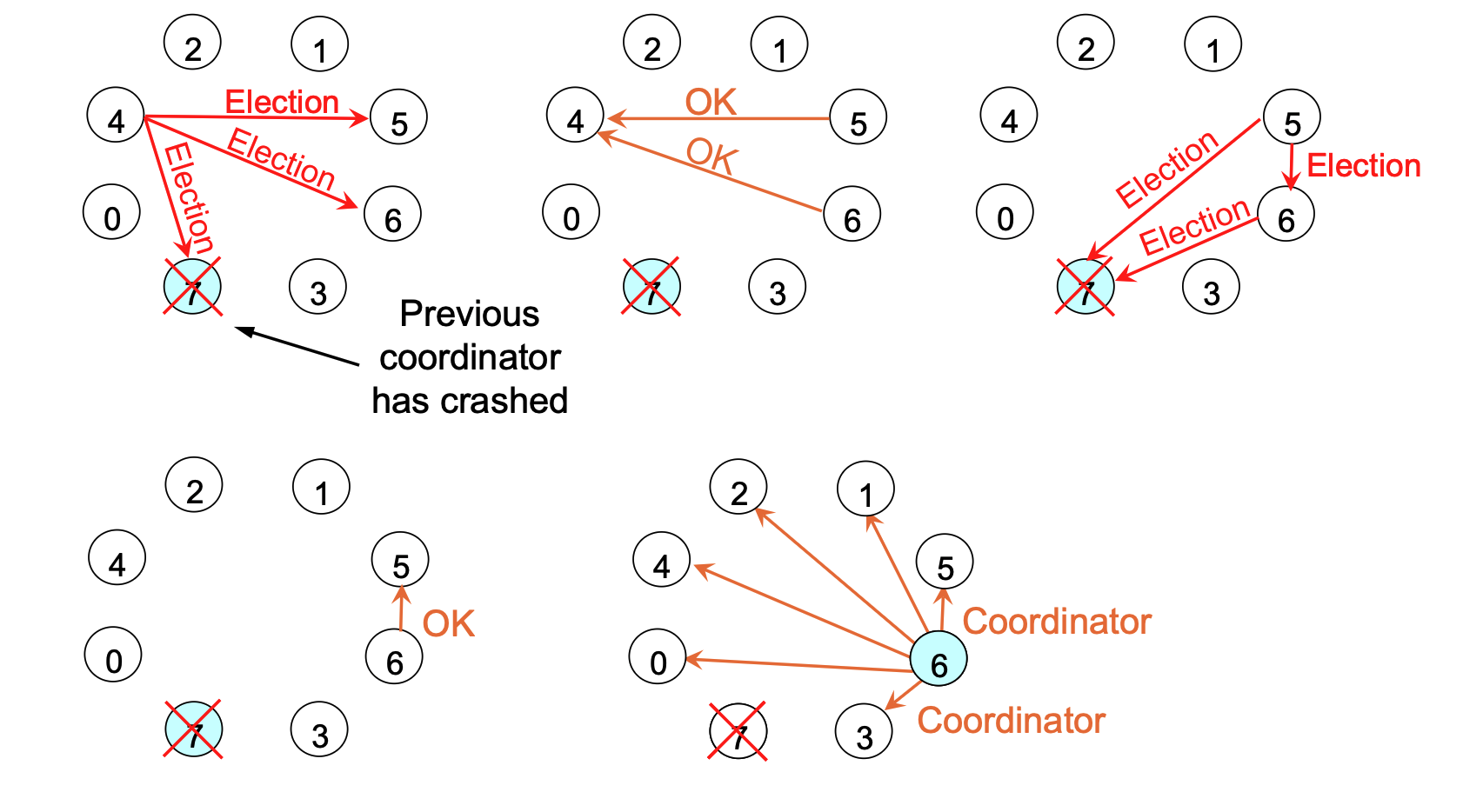
The Ring Algorithm¶
Mechanism
- Topology: Processes are ordered logically or physically in a ring; each knows its successor. No token is used.
- The Process:
- Start: When a process notices a coordinator crash, it builds an
ELECTIONmessage containing its own ID and sends it to its successor.- Any process notices that coordinator is not functioning could send the election message
- Skip Dead Nodes: If the successor is down, the sender skips it and tries the next node until a running process is found.
- List Building: Each process adds its own ID to the list inside the message and passes it on.
- Completion: When the message returns to the initiator (process recognizes the message containing its own process number), the list contains the IDs of all active nodes.
- Start: When a process notices a coordinator crash, it builds an
- Selection: The initiator scans the list, picks the highest ID as the new coordinator, changes the message type to
COORDINATOR, and circulates it again to inform everyone. When message has circulated once, it is removed.- Circulates message once again to inform everyone else: Who the new coordinator is (list member with highest number); Who the members of the new ring are.
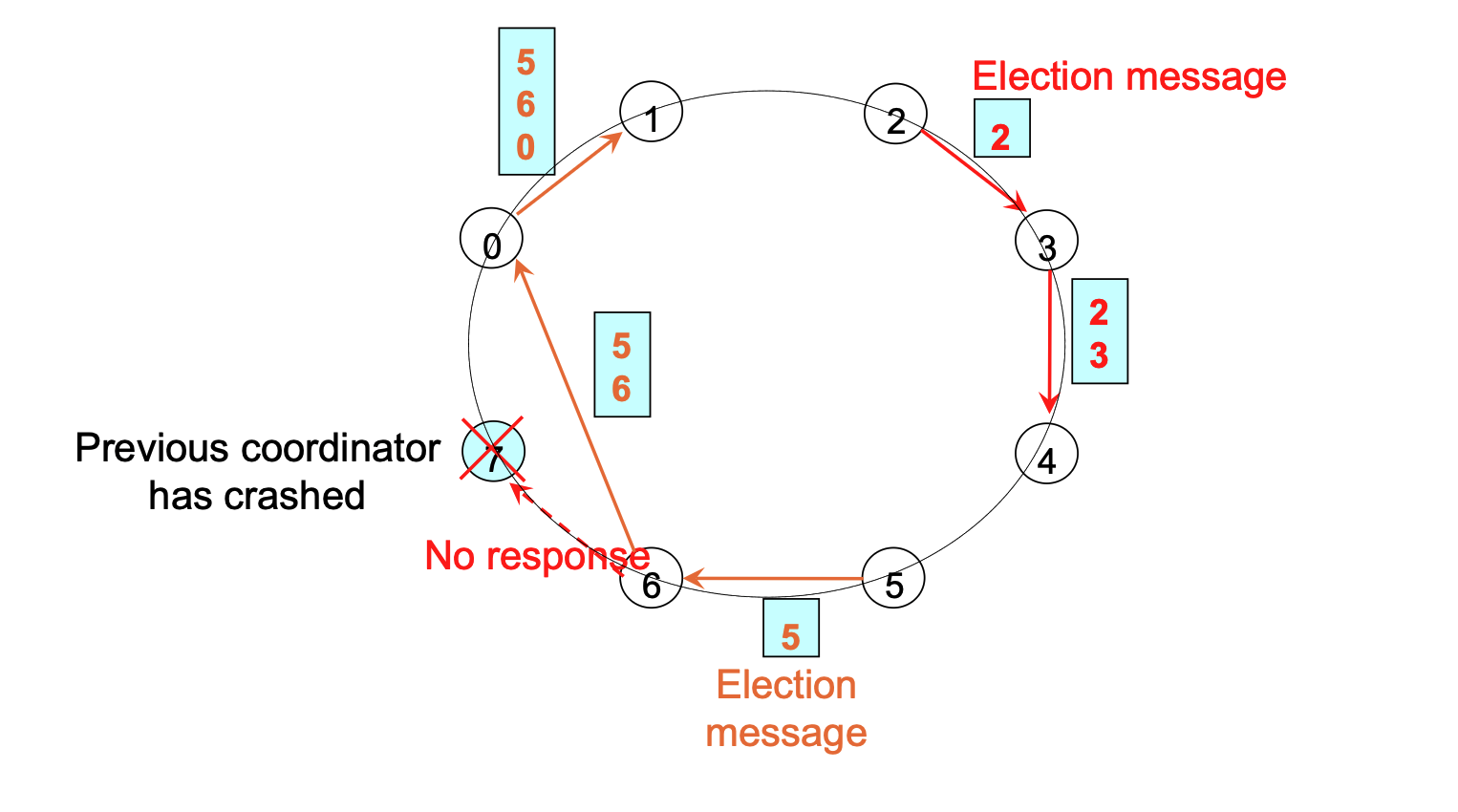
The two different colors (Orange and Red) represent two simultaneous elections happening at the same time.
- Concurrent Detection: In a distributed system, multiple processes might notice that the Coordinator (Process 7) has crashed at roughly the same time.
- Process 2 (Orange): Noticed the crash and started its own election message (sending to 3).
- Process 5 (Red): Also noticed the crash independently and started its own election message (sending to 6).
- No Conflict: The Ring Algorithm is designed to handle this. Both messages will circulate around the ring.
- The Orange message will collect the list:
[2, 3, 4, 5, 6, 0, 1]. - The Red message will collect the list:
[5, 6, 0, 1, 2, 3, 4].
- The Orange message will collect the list:
- Same Result: Even though two elections are running, the math remains the same. When Process 2 gets its message back, it sees that 6 is the highest number. When Process 5 gets its message back, it also sees that 6 is the highest number. They will both declare Process 6 the winner, so the system remains consistent.