Chord¶
Chord is a distributed lookup protocol built on top of consistent hashing.
Distributed Lookup and Consistent Hashing¶
Consistent hashing is the foundational technique used in systems like Chord to provide a scalable way to find data across many servers without moving massive amounts of data when the network changes.
Scalable Lookup Service¶
In distributed systems, looking up data is a core building block for key-value storage and directory services.
- The Problem: Classic hash tables fail in dynamic environments because changing the number of nodes (adding or removing a server) forces the system to move \(O(N)\) of the data to maintain the hash mapping, where \(N\) is the number of data items.
- The Solution: Consistent hashing maps both keys and nodes into a single circular naming space called a ring.
Consistent Hashing and the Ring¶
Consistent hashing solves the data movement problem by decoupling data keys from specific server IDs through a shared naming space.
- The Ring: Represents the entire range of possible hash values (typically \(0\) to \(2^m-1\)).
- Node Placement: A node's position is determined by hashing its IP address and placing it on the ring.
- Successor Rule: Each node is assigned an \(m\)-bit identifier. Every data entity has a unique \(m\)-bit key. It falls under the jurisdiction of its successor: the node with the smallest \(id \ge key\) (the first node encountered moving clockwise).
- “the first node encountered moving clockwise” is a logical (conceptual) model for defining ownership in consistent hashing
- The ring is an abstraction over a hash space, not a physical structure
- Nodes are machines on a network and are not physically arranged in a circle
- The successor of a key can be determined mathematically if the global set of node identifiers is known
- However, in a distributed setting:
- Nodes typically have only partial knowledge of the system (e.g., successor, predecessor, finger table)
- There is no global view of all node positions available locally
- Therefore, we cannot physically “walk clockwise” on the ring
- Instead, locating the successor requires a routing mechanism (e.g., iterative forwarding or finger tables)
- Constraint:
- Direct computation of the successor (i.e., no routing) is only possible if the querying entity (e.g., client) has up-to-date global knowledge of all node identifiers and the hash function
- To successfully find the node that owns the key, we need forwarding as discussed below.
- “the first node encountered moving clockwise” is a logical (conceptual) model for defining ownership in consistent hashing
- Local Knowledge: At a minimum, each node must know its immediate successor and predecessor to maintain the basic ring structure.
Request Routing and Optimization¶
The efficiency of a lookup service is measured by the number of "hops" required to locate a key.
Linear Lookup¶
In a basic implementation, a client contacts any node. If that node isn't the key's successor, it forwards the request to its own successor.
- Process: This continues sequentially around the ring until the key's successor is reached.
- Performance: \(O(N)\) hops. This is inefficient for large-scale networks.
- The Worst Case: If you contact a node and the key you are looking for is located on the node immediately "behind" you in the ring, the request must travel through every single other node to get there.
- The Average Case: On average, you’ll have to jump through \(N/2\) nodes.
- \(N\) is the number of nodes.
Finger Table Optimization¶
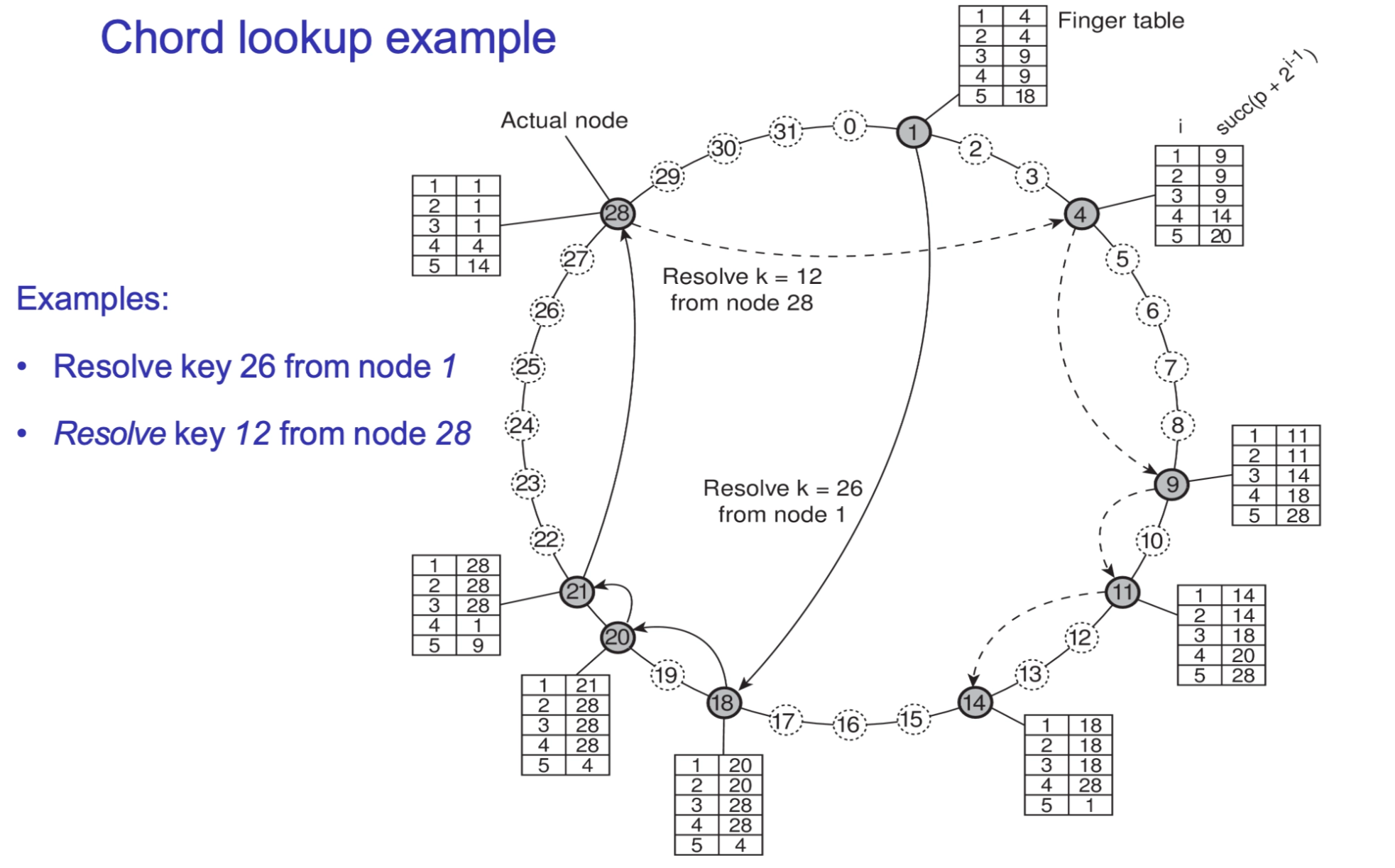
To achieve logarithmic performance, Chord nodes maintain a routing table called a Finger Table (\(FT\)).
- Structure: Each node \(p\) stores at most \(m\) entries (where \(m\) is the number of bits in the hash).
- Principle: The \(i\)-th entry points to the first node that succeeds \(p\) by at least \(2^{i-1}\) on the circle.
- Formula: \(FT_p[i] = \text{successor}(p + 2^{i-1}) \pmod{2^m}\), where \(1 \leq i \leq m\).
- Routing Logic: Node \(p\) searches its \(FT\) for a node \(q\) with index \(j\) such that \(FT_p[j] \le key < FT_p[j+1]\). It then "jumps" to \(q\), effectively halving the distance to the target with each hop.
- Direct Forwarding: If the key \(k\) is between node \(p\) and its first finger (\(FT_p[1]\)), it is sent directly to \(FT_p[1]\) (the immediate successor).
Performance and Reliability¶
Lookup Performance¶
The Finger Table turns a linear search into an exponential search, allowing a client to contact any node to initiate a search.
-
Efficiency: A lookup takes only \(O(\log N)\) steps.
- \(N\): The number of actual physical nodes (servers) currently in the network.
When you search for a key, a node doesn't just pass it to a neighbor. It looks at its finger table and finds the node that is closest to the key without overshooting it.
- Because the finger table entries are powers of 2, any node can jump at least halfway to the destination in a single hop.
- Once you arrive at that next node, the distance remaining to the key has been reduced by at least 50%.
- It is like binary search!
- Storage: Each node only needs to store \(O(m)\) routing information about the network.
- The table has exactly \(m\) entries.
Ring Reliability and Stabilization¶
Distributed rings must handle nodes failing or joining unexpectedly.
- Successor Lists: Each node stores a list of the next \(m\) successors. If the primary successor fails, the node uses the list to bridge the gap and keep the ring intact.
- Stabilization Function: Nodes periodically run a background function to:
- Check their successor's predecessor.
- If the answer is someone else, a new node has joined the ring, and the tables need to be updated.
- Only the immediate successor's!
- Discover if new nodes have joined between them and their successor.
- Adjust pointers to maintain the correct ring order.
- Check their successor's predecessor.
Node Join Process¶
When a new node joins, it follows a structured sequence to minimize disruption:
- Placement: The node performs a lookup for its own hash ID to find its correct position in the ring.
- Pointer Setup: It initializes its own successor and predecessor pointers.
- Integration: It runs the stabilization function to inform neighbors of its presence.
- Table Population: It gradually builds its Finger Table (often by copying relevant segments from its successor).
-
Data Efficiency: Only \(O(1/N)\) of the total system data needs to be moved when a new node joins, making the protocol highly scalable.
In Chord, every node is responsible for a specific segment of the ID ring. A node owns all keys that fall between its predecessor and itself.
- Before the join: If there are \(N\) nodes, the ID ring is divided into \(N\) segments. On average, each node stores \(1/N\) of the total data.
- During the join: A new node \((N+1)\) inserts itself between two existing nodes. It "slices" an existing segment in half.
Imagine a circle with \(1,000\) items distributed evenly.
- If there are \(1\)0 nodes, each node holds roughly \(100\) items (\(1/10\) of the data).
- When an \(11^{th}\) node joins, it doesn't take data from everyone. It only takes data from its immediate successor.
- It will take roughly half of its successor's load. Since the successor was holding \(1/N\), the new node takes roughly half of that (\(1/2N\)).
In Big O notation, we ignore the constant (\(1/2\)), leaving us with \(O(1/N)\).
When a node joins, the Finger Tables (FT) across the network do not update instantly. They become stale (outdated).
Here is exactly how Chord handles that "backwards" handoff and how the tables eventually catch up.
The "Handoff"¶
If Node A has a stale Finger Table and wants to look up a key that should now belong to the New Node, it will likely send the request to the Successor (the node that used to own that key).
- The Check: When the Successor receives the request, it checks its Predecessor pointer.
- The Redirection: Because of the Stabilization process, the Successor already knows its new predecessor is the New Node.
- The Result: The Successor realizes, "Wait, this key is actually behind me now (it belongs to my new predecessor),"and it forwards the request back to the New Node.
Why it doesn't break the system¶
The system remains correct even if the Finger Tables are wrong, as long as the Successor pointers are correct.
- Successor Pointers = Correctness: As long as every node knows its immediate next neighbor, you can always find a key (even if it takes \(O(N)\) hops in the absolute worst-case while tables are updating).
- Finger Tables = Performance: Finger tables are just "shortcuts." If they are outdated, the lookup might take a few extra hops, but it will still eventually arrive at the right destination by following the ring.
How the Finger Tables "Fix" Themselves¶
Chord nodes don't update their entire Finger Tables the moment someone joins. That would cause a massive "broadcast storm" of traffic. Instead, they use Lazy Updating:
- Stabilization: Nodes periodically talk to their immediate neighbors to ensure the ring is joined correctly.
- Fixing Fingers: Each node runs a background process that periodically picks a random entry in its Finger Table and refreshes it by performing a fresh lookup.
- Gradual Accuracy: Over time, the "news" of the new node ripples through the network. The Finger Tables eventually point to the New Node, and the \(O(\log N)\) efficiency is restored.