Replication¶
Replication in Distributed Systems¶
Fundamentals of Replication¶
Logical vs. Physical Objects
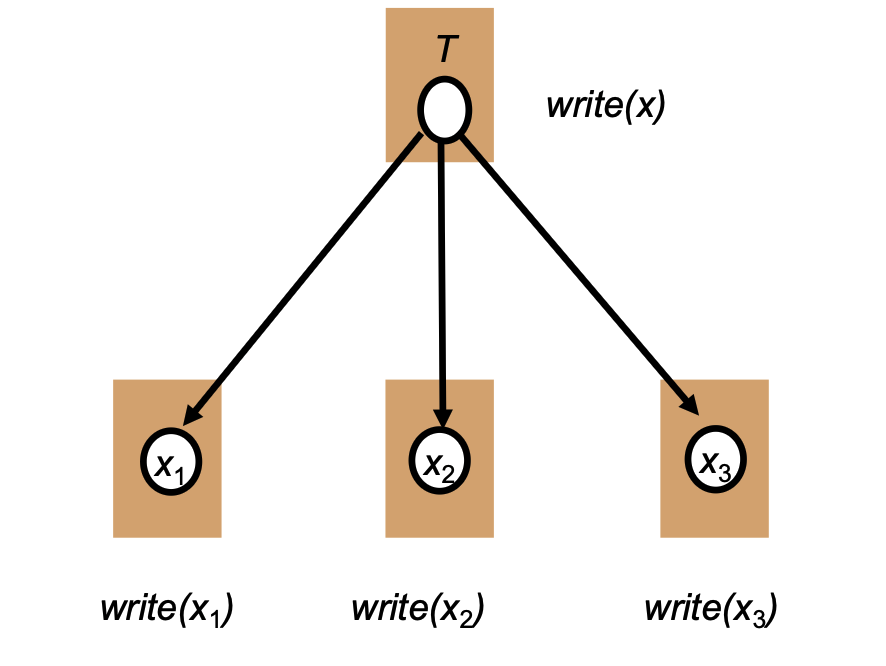
- Distributed systems maintain physical copies of logical objects.
- Operations are specified on the logical object (e.g., \(T\)) but are translated to operate on the individual physical replicas (e.g., \(x_1, x_2, x_3\)).
Motivation
- Why Replicate? It improves reliability by avoiding single points of failure, and it enhances performance by providing scalability in numbers (of users and recources) and across geographic areas.
- Why Not Replicate? It creates challenges with replication transparency, and introduces consistency issues because updates are costly and availability may suffer if not managed carefully.
General Architecture¶
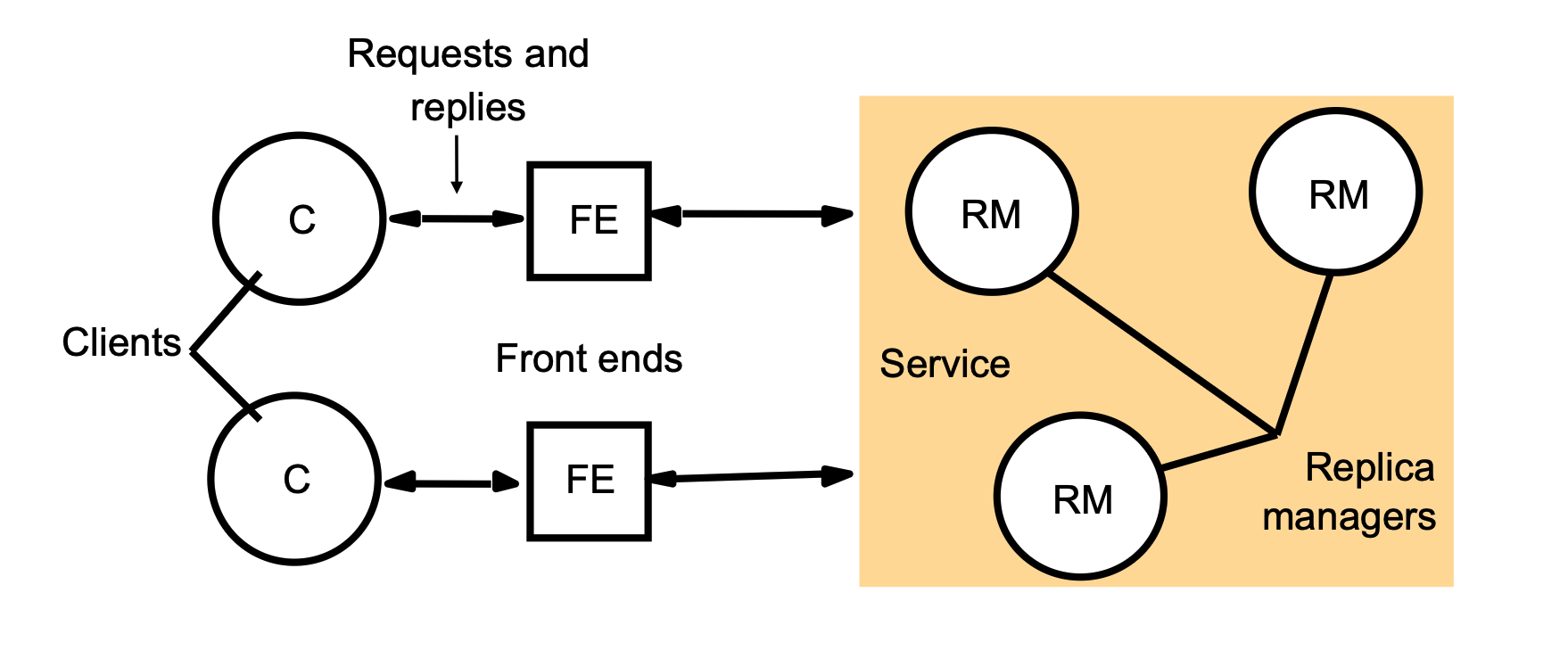
- Clients (\(C\)) send requests and receive replies from "Front ends" (\(FE\)).
- The front ends communicate with the core "Service," which consists of multiple "Replica managers" (RM) storing the data.
Replica Placement Strategies¶
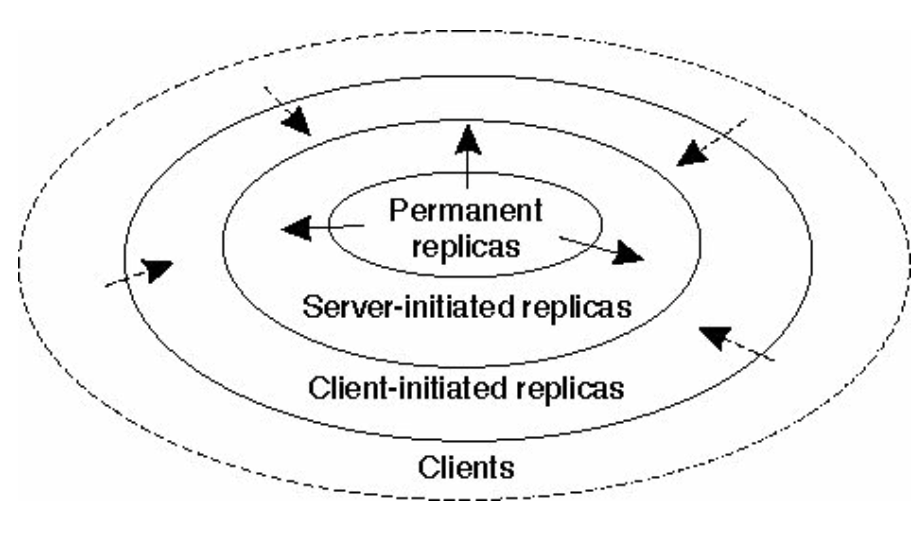
Systems use a hierarchy of strategies to decide where to place replicas:
- Permanent Replicas: Placed at a number of specific, fixed locations (e.g., Mirroring).
- Server-Initiated Replicas: The server autonomously decides where and when to place replicas (e.g., Push caches).
- Push caching (also known as server-initiated caching) is a strategy where the server "pushes" updates or data to a client’s cache before the client even asks for it.
- Client-Initiated Replicas: Data stored directly near the client (e.g., Client caches).
- Client decides what to keep and when to refresh it.
Update Propagation¶
What to Propagate When data changes, the system can propagate different types of information:
- Notification: Sending only an invalidation message.
- Updated Data: Sending the new data itself, possibly just using logs.
- Update Operation: Sending the exact operation to be executed on all replicas (used in Active replication).
- Active Replication is a technique where every replica in a distributed system is treated as an "active" participant that processes every incoming request independently.
- Instead of one master node doing the work and then telling the "slaves" the result, in active replication, the client (or a multicast service) sends the actual operation (e.g.,
update balance = balance + 50) to every single replica simultaneously.
Push vs. Pull Protocols Updates can be driven by the server (Push) or the client (Pull).
| Issue | Push-based | Pull-based |
|---|---|---|
| State of server | Maintains a list of client replicas and caches. | None. |
| Messages sent | Sends updates (and possibly fetches update later). | Client must poll and update. |
| Response time at client | Immediate (or fetch-update time). | Fetch-update time. |
These protocols describe how updates are moved from a central server to various replicas or caches. The choice between them represents a trade-off between server complexity and client speed.
1. State of Server (Memory Overhead)
- Push-based: The server is "stateful." It must maintain a detailed list of every client replica and cache that exists. The server takes responsibility for knowing who needs the data.
- Pull-based: The server is "stateless." It has no idea who is using its data. This makes the server much simpler and easier to scale because it doesn't have to manage a massive address book of clients.
2. Messages Sent (Communication Flow)
- Push-based: The server initiates the conversation. As soon as data changes, the server "pushes" the update (or a notification) to the clients.
- Pull-based: The client initiates the conversation. The client must periodically "poll" (ask) the server: "Is there anything new?". If there is, the client then pulls the update.
3. Response Time at Client (User Experience)
- Push-based: This is usually faster. Because the server sends the data as soon as it's ready, the client often has the new version immediately.
- Pull-based: This is slower. If a client only checks every 10 minutes, and an update happens at minute 1, the client will be out-of-date for 9 minutes. The response time includes the fetch-update time (the time it takes to ask and receive).
Replication Protocols¶
Protocols are broadly categorized into Primary-based protocols (like Remote-Write) and Replicated Write protocols (like Active replication and Quorum-based protocols).
Primary Copy Remote-Write Protocol¶
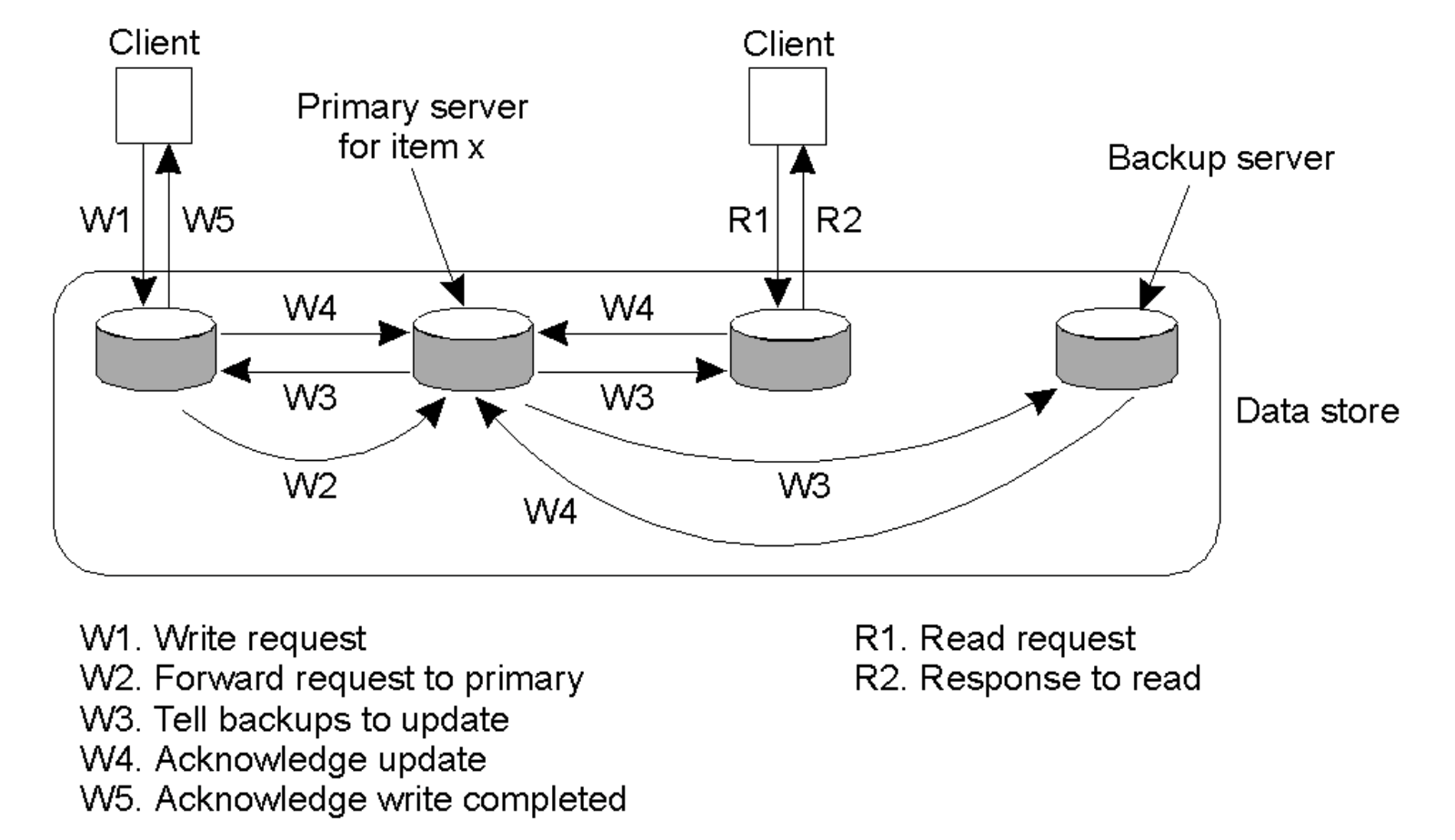
- Write Flow: A client sends a write request (\(W1\)) to a central "Primary server". The Primary server forwards the update to "Backup servers" (\(W3\)), waits for them to acknowledge the update (\(W4\)), and finally acknowledges the completed write back to the client (\(W5\)).
- The primary server will do the computation and pass the value to the replicas to update directly.
- Read Flow: A client can send a read request (\(R1\)) directly to a Backup server and receive a response (\(R2\)) without burdening the Primary server.
Active Replication¶
-
Mechanism: Requires a dedicated process for each replica that is capable of performing the update locally.
Instead of just copying data from a primary server, each replica "actively" performs the computation itself.
- Operation Propagation: When a client wants to change data, it doesn't just send the new value; it sends the update operation (the command) to all replicas.
- Total Ordering: To ensure all replicas end up with the exact same data, every replica must execute the commands in the same order. This usually requires a "totally-ordered multicast" mechanism, often implemented using Lamport timestamps.
- You can’t use causal order because it does NOT guarantee a single global timeline. For concurrent requests, different replicas can see different orders. It only guarantees If A → B (A causally happens before B), then everyone sees A before B.
- Total order is needed because all replicas must execute in the exact same order.
In Active Replication, the request usually goes through a Front End (FE) rather than a single "Primary Server".
Here is how the communication flow actually works:
The Role of the Front End
- Instead of a client talking to one specific server, it sends the request to a Front End.
- The Front End's job is to multicast that operation to every single Replica Manager (RM) in the group.
No "Middleman" Primary
- Unlike the Primary-Copy model (where a single Primary server receives the data, processes it, and then tells the backups what happened), Active Replication treats all replicas as equals.
- Every replica receives the exact same operation at the same time and performs the work itself.
- Ordering Constraint: To ensure consistency, the exact update order must be enforced across all replicas using a totally-ordered multicast mechanism, which can be implemented via Lamport timestamps.
- The "Replicated Invocations" Problem: If a replicated object \(A\) invokes another object \(B\), every single replica of \(A\) will independently invoke \(B\), resulting in problematic multiple invocations.
Replicated Invocations & Consistency Models¶
The Replicated Invocations Problem¶
The Issue
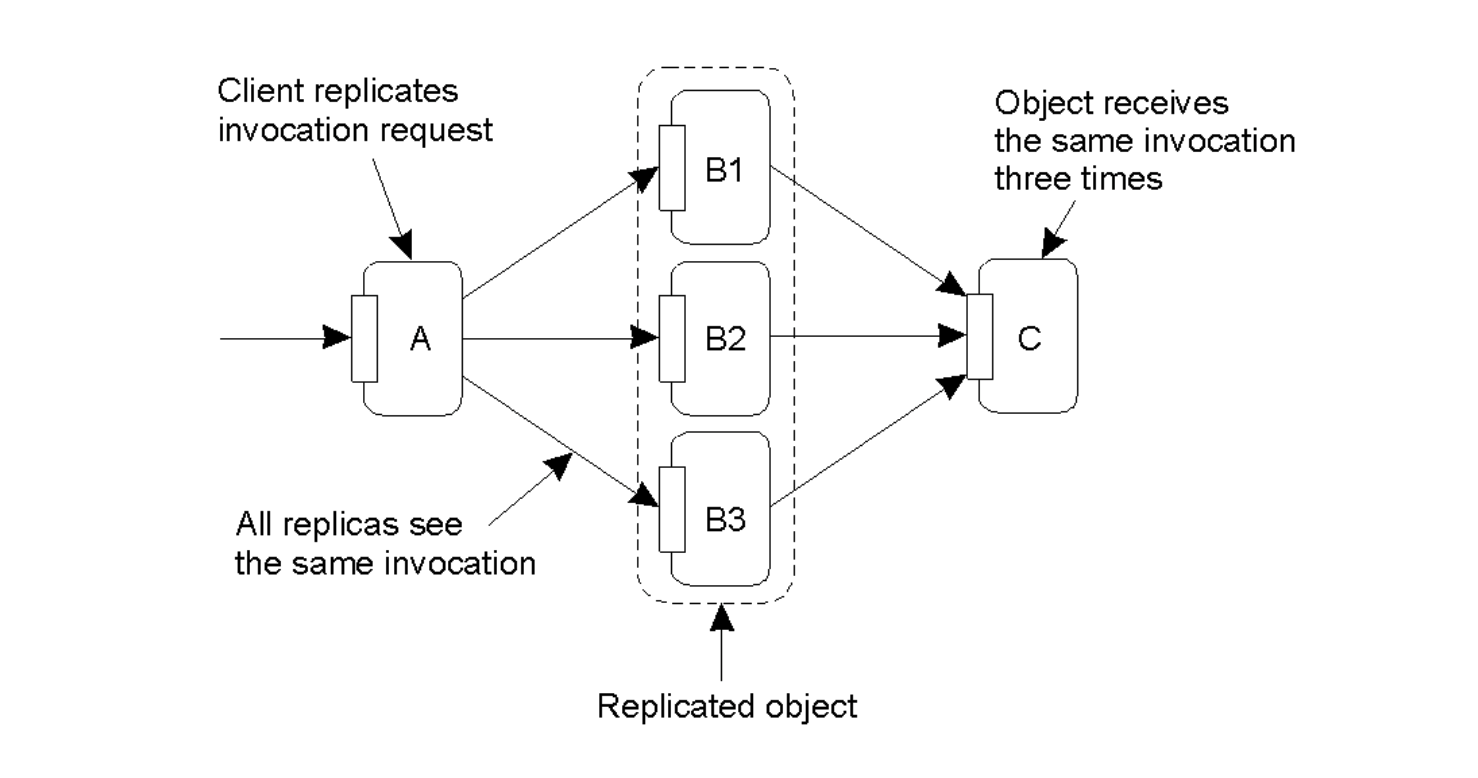
- If a replicated object \(B\) (which has multiple replicas) needs to invoke another object \(C\), a problem arises if every replica of \(B\) independently makes the call.
- Result: The target object \(C\) will receive the exact same invocation request multiple times (e.g., three times if \(B\) has three replicas), leading to redundant processing or corrupted state .
The Solution
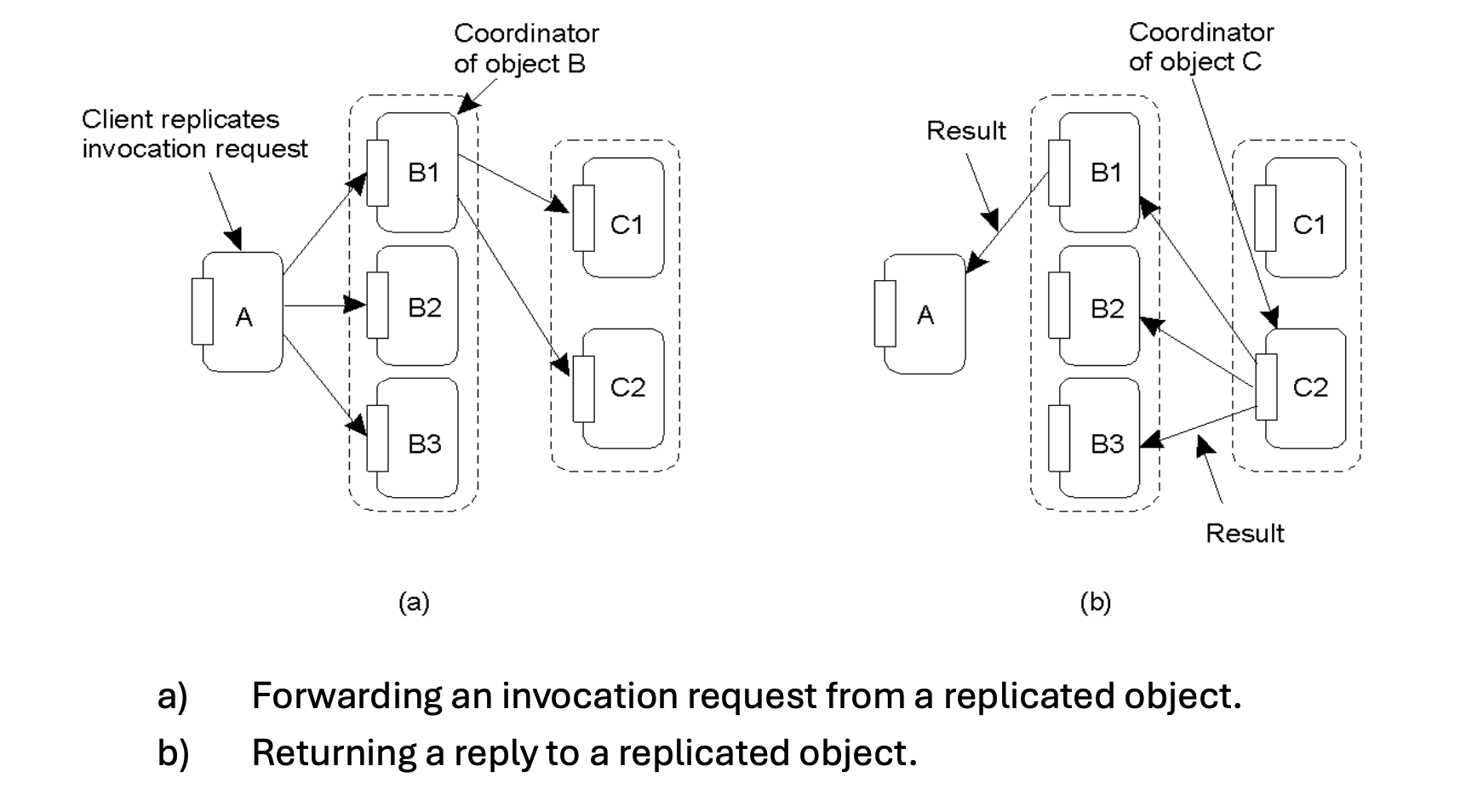
- Forwarding: Instead of all replicas sending the request, one replica of the calling object is designated as the Coordinator. Only the coordinator forwards the invocation request to the target object.
- Replying: Similarly, when returning the result, the coordinator of the target object sends the reply back to the replicated calling object.
B2 and B3 will also receive an execution of the invocation. When the code in B2 and B3 attempts to call the function on object C, the function call is suppressed and only the coordinator makes the remote call. The coordinator of object C returns the result of the invocation to B1, B2, and B3.
Introduction to Consistency Models¶
Purpose
- Consistency models define how a distributed system reasons about the consistency of its "global state" when multiple processes are reading and writing data.
- Two Main Categories:
- Data-centric consistency: Focuses on the system's global view of the data (e.g., Sequential Consistency).
- The entire system behaves consistently for all clients
- All clients see the same order / same values
- Client-centric consistency: Focuses on what an individual client observes (e.g., Eventual Consistency).
- A single client sees reasonable / consistent behavior
- But different clients may see different states
- Data-centric consistency: Focuses on the system's global view of the data (e.g., Sequential Consistency).
Sequential Consistency¶
Definition & Criteria¶
A data store is considered sequentially consistent if the execution results satisfy two strict rules:
- Global Order: All read and write operations by all processes must be executed in some sequential order.
- Local Program Order: The operations of each individual process must appear in this global sequence in the exact order specified by that process's original program.
- The Core Rule: This implies that all processes must see the exact same interleaving of operations. If Process 3 sees Write \(A\) happen before Write \(B\), Process 4 cannot see Write \(B\) happen before Write \(A\).

This diagram is only showing observations of the local order of operations as seen by each individual process. It is NOT a global timeline, neither the actual execution order.
So it is really asking “Can I find ONE global order that explains ALL these observations?” If yes, it is sequentially consistent.
The left one is sequentially consistent as we can find a global order such that W(x)b → W(x)a is valid. For the right one, it is not since it indicates both W(x)b → W(x)a from P3 and W(x)a → W(x)b from P4, which is not possible and invalid.
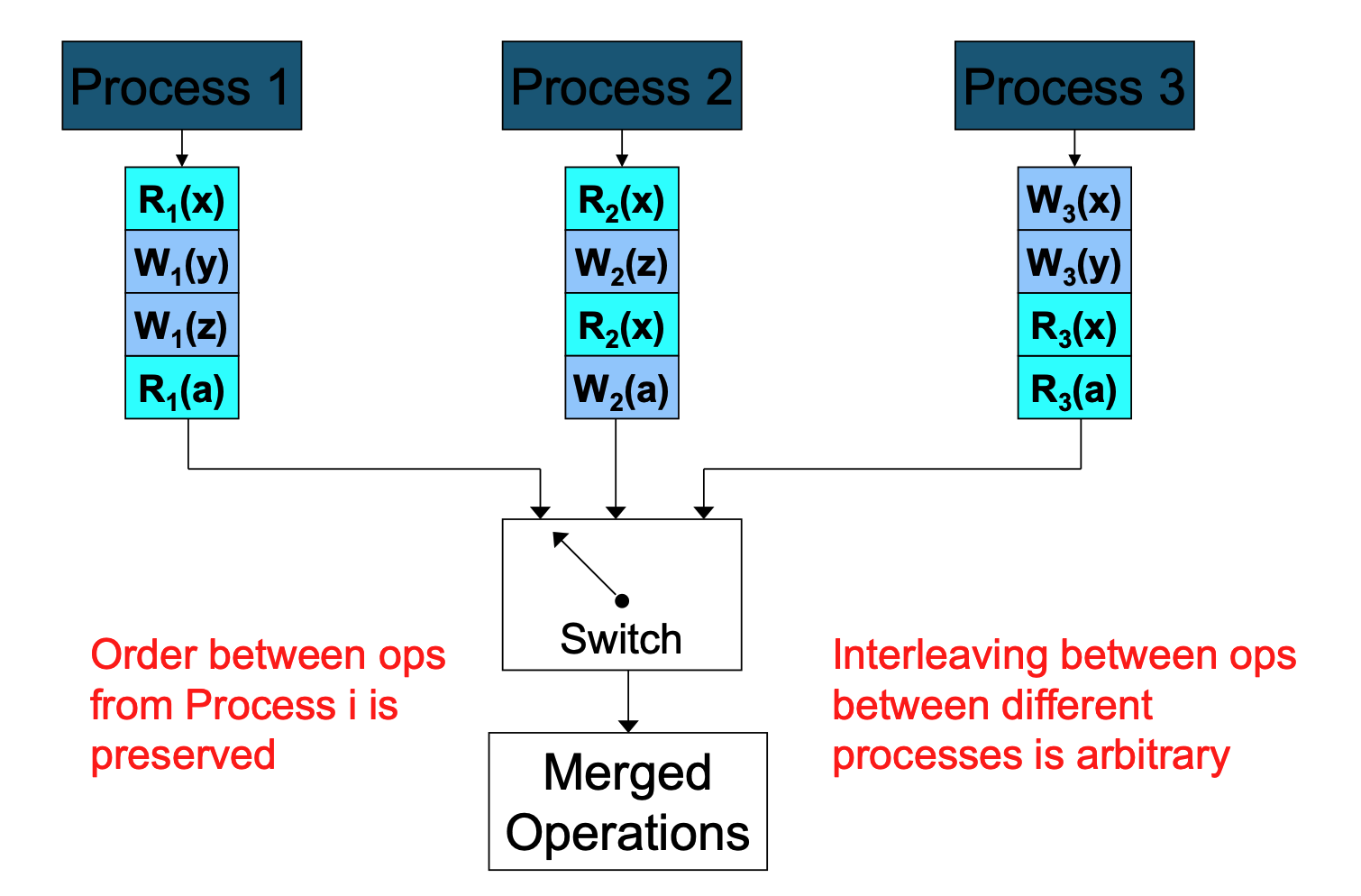
The Logical View (The "Switch" Analogy)¶
- Imagine all processes feeding their operations into a central switch .
- Arbitrary Interleaving: The switch can rapidly flip back and forth between processes, meaning the interleaving between operations from different processes is arbitrary.
- Preserved Order: However, the switch cannot reorder the queue coming from a single process. The order between operations originating from Process \(i\) is always strictly preserved in the final merged stream.
Additions¶
When two processes attempt to write to the same critical region after completing a read, the system's behavior depends on which Mutual Exclusion or Consistency algorithm is being used. Here is how the different models you've studied handle this "race condition":
In Mutual Exclusion Algorithms
The goal of these algorithms is to prevent this exact scenario from happening simultaneously.
- Centralized Algorithm: The Coordinator acts as a judge. Even if both processes finished their "read" and now want to "write," they must both send a
Requestto the coordinator. The coordinator will grant permission to one (sendingOK) and queue the other, forcing it to wait until the first one sends aRelease. - Distributed (Ricart-Agrawala): The processes use Lamport Timestamps to break the tie. Both will broadcast their write requests to everyone. Each process compares the timestamps: the one with the lower (older) timestamp wins the right to enter the region first. The "loser" is queued and must wait for an
OKfrom the winner.
In Sequential Consistency
If the "write" isn't protected by a formal mutual exclusion lock, Sequential Consistency dictates how the rest of the system perceives those two writes.
- The "Switch" Rule: The system's logical "switch" must pick one write to happen before the other. It might pick P1 then P2, or P2 then P1.
- Global Agreement: The most critical requirement is that every process in the system must see the same order. If the system decides P1 wrote first, then every single node must show P1's value being overwritten by P2's value. You cannot have one node thinking P1 was the final update while another node thinks P2 was the final update.
Mutual Exclusion and Sequential Consistency are layers that work together to keep a system from falling apart.