2PC¶
Distributed Transactions & Atomic Commit¶
Two-Phase Commit (2PC)¶
The Concept
- Distributed systems use Two-Phase Commit to ensure atomicity across multiple sites participating in a transaction.
- Coordinator: The site where the transaction originates; it controls the execution.
- Participants: The other sites that execute the transaction.
The Two Phases
- Phase 1 (Voting): The coordinator gets participants ready to commit. It sends a "Vote?" request to all participants.
- Phase 2 (Completion): Based on the votes, everybody either commits or aborts the transaction.
Global Commit Rules
- Abort: The coordinator aborts the transaction if at least one participant votes to abort.
- Commit: The coordinator commits if and only if all participants vote to commit.
Centralized 2PC Communication¶
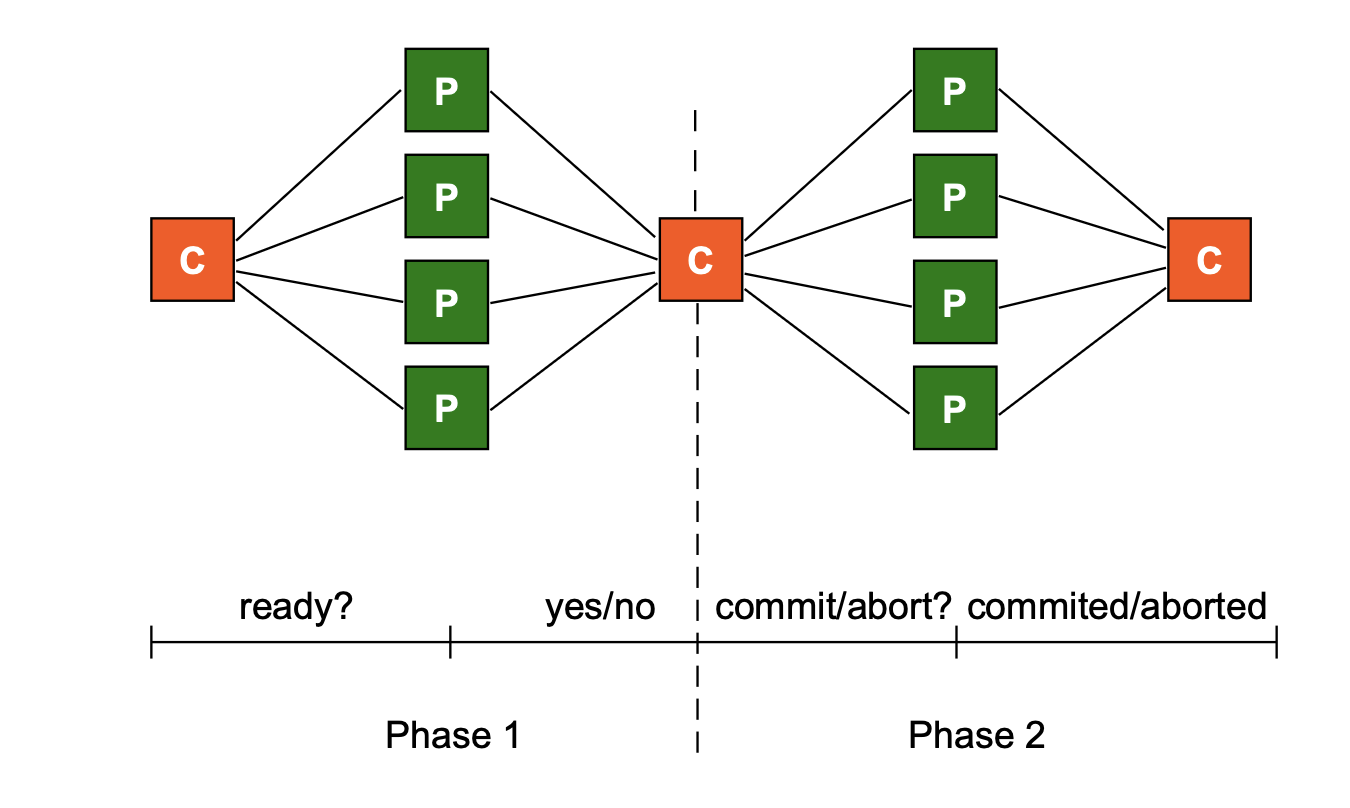
Message Flow
- Request: A client sends a request to the coordinator.
- Voting: Coordinator sends "Vote?" to participants. Participants reply with "Commit" or "Abort".
- Decision: Coordinator broadcasts the final decision (Commit/Abort) to all participants.
- Acknowledgment: Participants send an "ack" back to the coordinator. The coordinator then acknowledges the client.
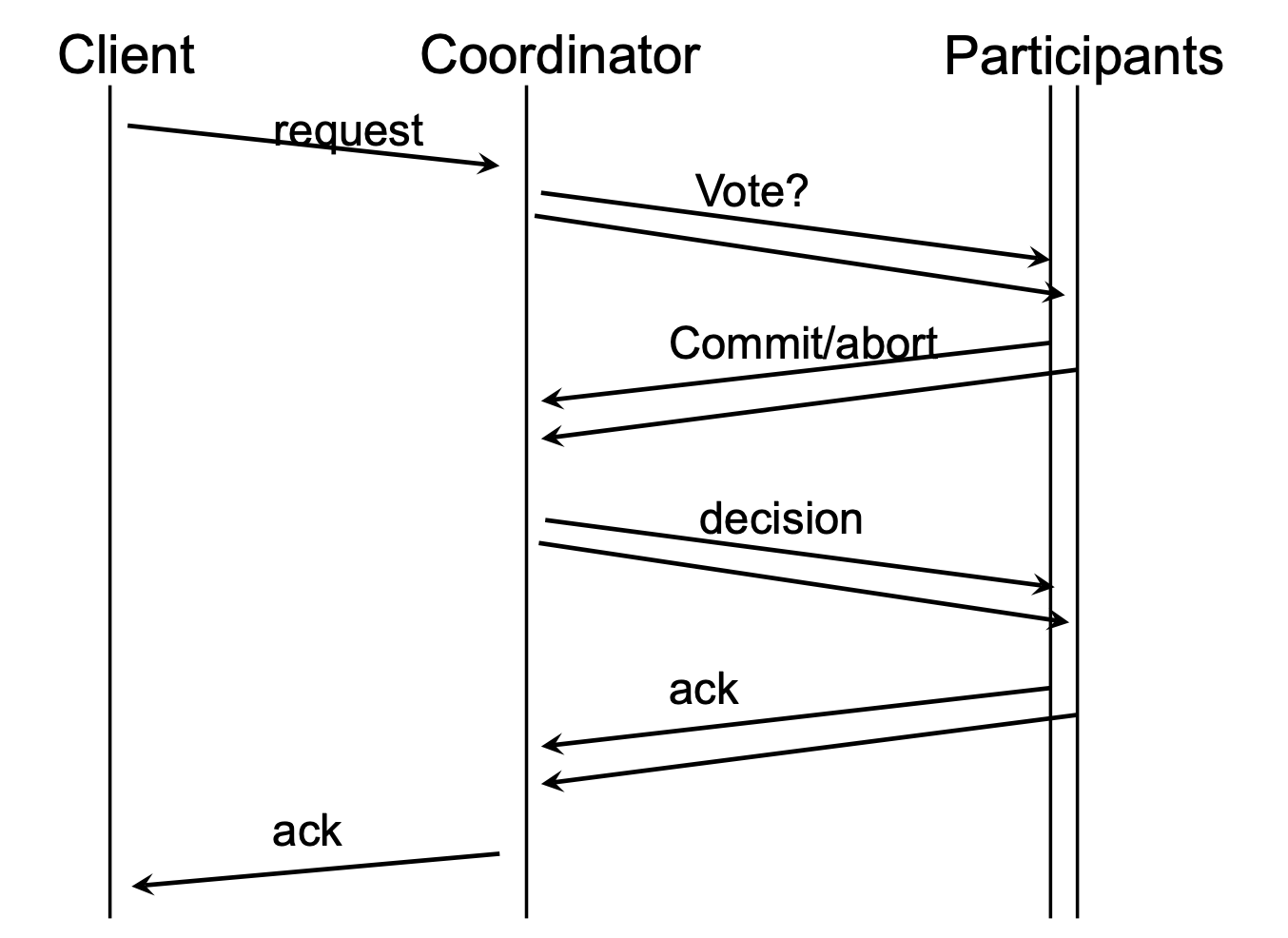
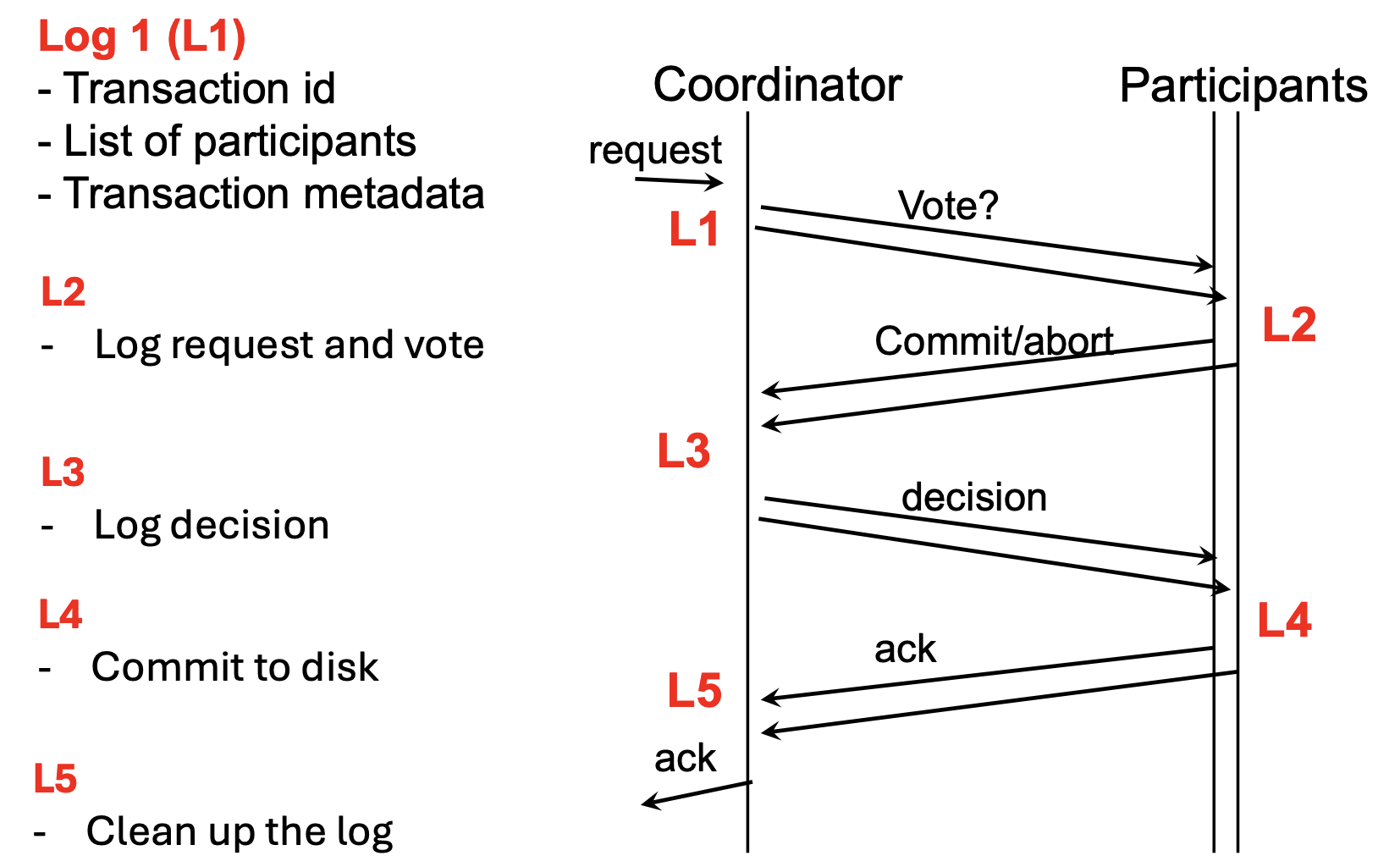
Logging and State Management (2PC State)¶
To handle failures, the protocol uses persistent logs at both the coordinator and participant sides:
- L1: Coordinator logs the transaction ID, participant list, and metadata.
- L2: Participants log the request and their local vote.
- L3: Coordinator logs the final global decision.
- L4: Participants commit the transaction to disk.
- L5: Coordinator cleans up the log after receiving all acknowledgments.
- The cleanup at L5 signifies the formal end of the coordinator's responsibility for that specific transaction ID. It safely removes the "trail" of intermediate states because the "Global Commit" is now a permanent fact across the entire distributed system.
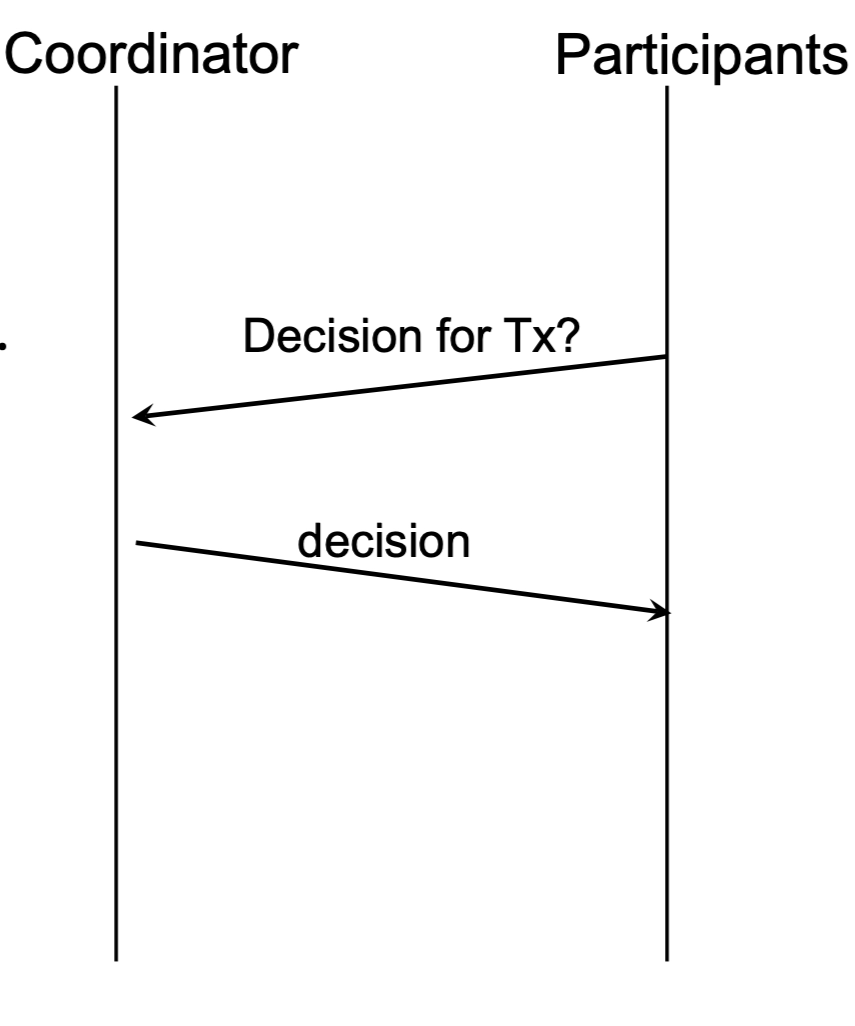
Failure Recovery¶
- Coordinator Role: Beyond coordinating commits, it must maintain a copy of the database and answer questions from participants about old transactions.
- Participant Inquiry: If a participant is uncertain about a transaction (e.g., after a crash), it can ask the coordinator for the decision.
2PC Failures and Error Handling¶
Overview of 2PC Failures¶
The Two-Phase Commit (2PC) protocol must be robust against failures at various points in the communication cycle between the Coordinator and Participants. Failures are handled through a combination of timeouts, log checks, and status queries.
Failure Scenarios and Solutions¶
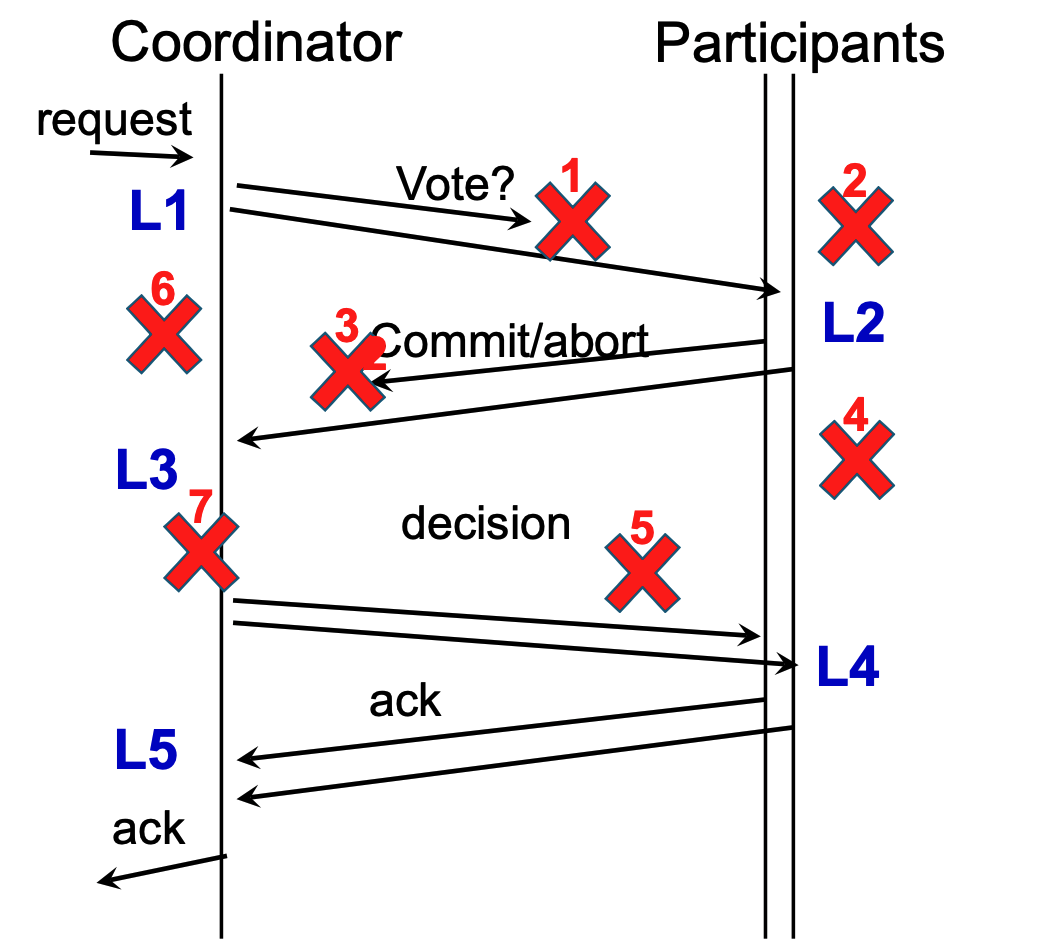
If you haven't reached the decision (L3), the safest answer is always "Abort." This is why points 1, 2, 3, and 6 all result in an Abort. The system only moves forward to a "Commit" if it is 100% sure every single piece of the puzzle is in place.
The system identifies seven critical failure points (marked 1-7 in diagrams) and provides specific recovery logic for each:
| Point | Failure Event | Specific Timing & State | Immediate Action / Outcome | Detailed Explanation & Solution |
|---|---|---|---|---|
| 1 | Request Message Lost | Phase 1 Initiation: During the initial multicast of the "Vote?" request. | Abort. | The Coordinator sends "Can Commit?" but it never reaches the Participant. The Participant never knows a transaction started. The Coordinator waits, gets no reply, and eventually Aborts. |
| 2 | Participant Crash | Pre-Voting: After receiving "Vote?" but before sending a reply. | Abort. | The coordinator cannot reach a unanimous decision without this vote. It waits for a timeout period and then issues a global Abort. |
| 3 | Vote Message Lost | Uncertain Phase: After sending a "Commit" vote but before receiving a decision. | Abort. | The Participant sends a "Commit" vote, but it never reaches the Coordinator. Same as above—silence from a participant leads to a timeout and an Abort. |
| 4 | Participant Crash | Post-Decision: Before receiving the global decision but after sending "Commit" vote. | Log Check & Query. | Upon restart, the participant checks its local log (L2). If its vote was "Abort," it's safe to abort. If its vote was "Commit," it is in an uncertain state and must ping (check with) the coordinator to learn the final outcome. |
| 5 | Decision Message Lost | Decision Delivery: While broadcasting the final Commit/Abort. | Timeout \(\rightarrow\) Ping/Pull. | If the decisions doesn't arrive (because the message was lost), the Coordinator's timer goes off. The Coordinator thinks, "Maybe the participant didn't get my decision." It retries by re-sending the "Global Commit" message. It will keep doing this until it finally gets that ACK. |
| If the Participant doesn't hear from the Coordinator, its own timer goes off. The Participant thinks, "I've been 'Prepared' for too long. I need to know the result." It sends a "What is the decision?" message to the Coordinator. So they need to check with the coordinator. | ||||
| 6 | Coordinator Recovery | Post-Restart (Phase 1): Waking up after a crash that occurred before logging a decision. | Consult Log \(\rightarrow\) Abort. | On restart, the coordinator checks its disk. Finding no L3 (Decision) log entry, it realizes the transaction was incomplete and tells all inquiring participants to Abort. |
| 7 | Coordinator Recovery | Post-Restart (Phase 2): Waking up after crashing during the decision multicast. | Consult Log \(\rightarrow\) Answer Queries. | The coordinator finds the L3 "Commit" entry in its persistent log. It then answers queries about previous transactions from participants to finish the synchronization. |
Summary of Logic
- Points 1, 2, 3: Result in an Abort because the agreement is incomplete.
- Point 4 & 5: Require checking with the coordinator to see if the global decision was already reached.
- Point 6 & 7: Rely on the coordinator restarting and checking its logs to either abort or answer participant queries.
Clarifying Points 6 and 7¶
Points 6 and 7 are about "The Recovery Process":
These describe what a node does after it wakes up from a crash.
- In Point 6 (Phase 1 recovery): The Coordinator wakes up, looks at its disk, and sees it only got as far as "L1" (starting the transaction). Since there is no "L3" (Decision), it tells everyone "I crashed, so we are aborting".
- In Point 7 (Phase 2 recovery): The Coordinator wakes up, looks at its disk, and sees an "L3" entry saying "Commit". It now knows the transaction was successful and can tell any waiting participants: "The decision was Commit, you can finish now".
Points 6 and 7 represent the Coordinator's recovery process after it has already crashed and is now attempting to reboot.
What "Permanent Failure" Means¶
A permanent failure occurs if the Coordinator (at point 6 or 7) or a Participant (at point 4) crashes and never reboots(e.g., the hardware is physically destroyed).
In the 2PC protocol, this leads to a critical problem called Blocking:
- The Problem: If the Coordinator is permanently gone, the Participants are stuck in an "uncertain" state. They have voted "Commit," but they cannot finalize the transaction because they don't know the global decision.
- The Constraint: Participants cannot simply decide to abort or commit on their own because that might break the atomicity rule (one node might commit while another aborts).
- The Result: The entire system "blocks"—the resources (like database rows) remain locked indefinitely, and no other transactions can use them until the failed node is manually recovered or replaced.
If a participant crashes and never comes back, the Coordinator doesn't wait forever, but the data stays locked forever. It doesn't "wait" in the sense that it stops working—it can handle other transactions—but it cannot write L5 (Cleanup). As long as one participant hasn't sent an ACK, the Coordinator must keep that transaction "alive" in its memory/logs just in case the node eventually wakes up.
Key Recovery Mechanisms¶
- Persistent Logging: Both parties must log their state (L1-L5) to disk to ensure they can determine the transaction status after a reboot.
- Participant Inquiry: If a participant crashes and recovers at Point 4, it must verify the final outcome with the coordinator if its local vote was "commit".
- Handling Permanent Failure: If the coordinator suffers a permanent failure at points 6 or 7, the remaining active nodes will block (wait indefinitely) because the global state cannot be safely determined.
The Locking Life Cycle¶
To prevent "lost updates" or inconsistent reads during a transaction, the system locks the relevant data regions.
- Ready State & Locking (Phase 1 of 2PC): During normal transaction execution, participants acquire locks on the data they read or write (at L2). When the coordinator sends a “Vote?” request, the participant checks whether it can commit. If it can, it writes its vote record to its log and sends a YES vote, thereby entering the READY state.
- The participant must already hold all required locks when voting YES and must keep these locks until the final COMMIT or ABORT decision, ensuring the transaction can still be completed exactly as promised.
- The "Uncertain" Period: From the moment a participant writes its vote to the log (L2) until it receives the final decision, the resources remain locked.
- Unlocking (After L4): Participants only release the locks after they have successfully committed (or aborted) the data to the disk at step L4.
The Core Difference¶
- Replication is about Availability. You want multiple copies of the same thing so that if one node dies, the service stays online.
- 2PC (Two-Phase Commit) is about Consistency (Atomicity). You want to make sure that a single "logical" action that affects different pieces of data happens everywhere or nowhere.