Raft¶
Raft Consensus Algorithm¶
The Raft algorithm focuses on managing a replicated log to ensure that all servers in a distributed system execute the same commands in the same order, creating a replicated state machine.
Core Architecture¶
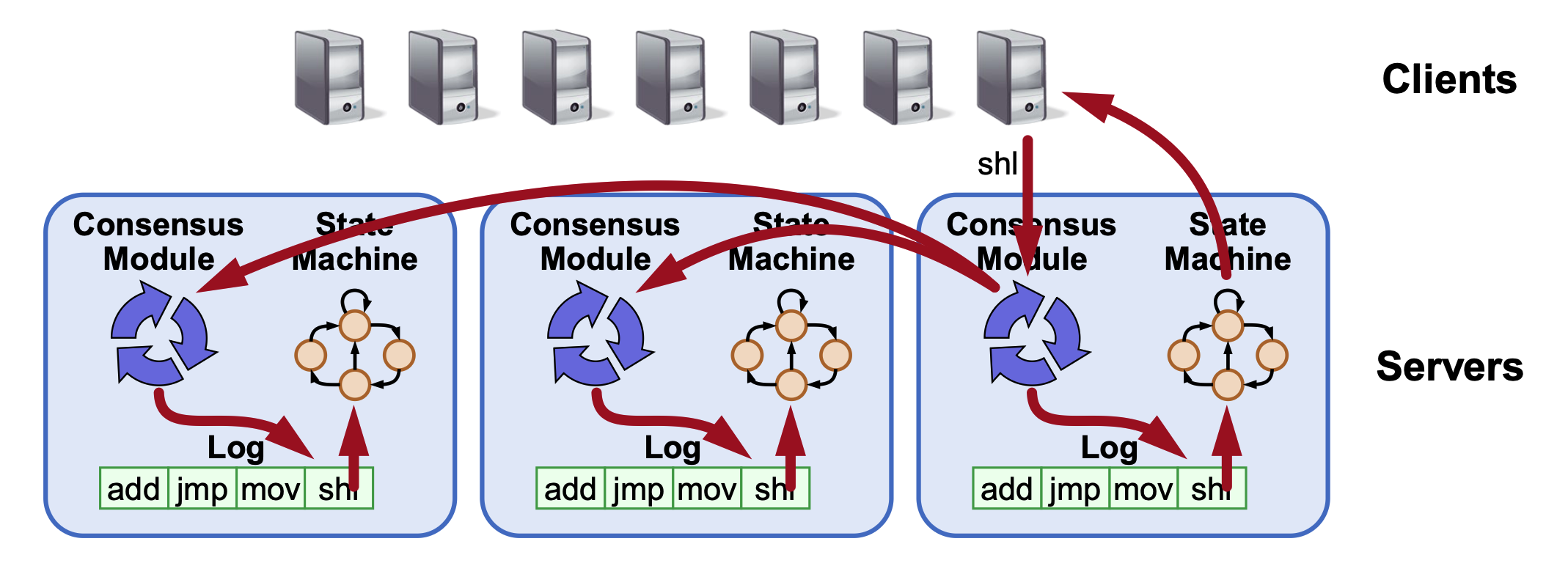
- Consensus Module: Each server has a module that ensures proper log replication across the cluster.
- Majority Rule: The system makes progress as long as a majority of servers are operational.
- Failure Model: Designed for fail-stop (not Byzantine) conditions, handling delayed or lost messages.
- Leader-Based: Raft uses a single leader to decompose the problem into normal operation and leader changes, which simplifies the process and eliminates conflicts, and is more efficient than leader-less approaches.
Terms and Elections¶
-
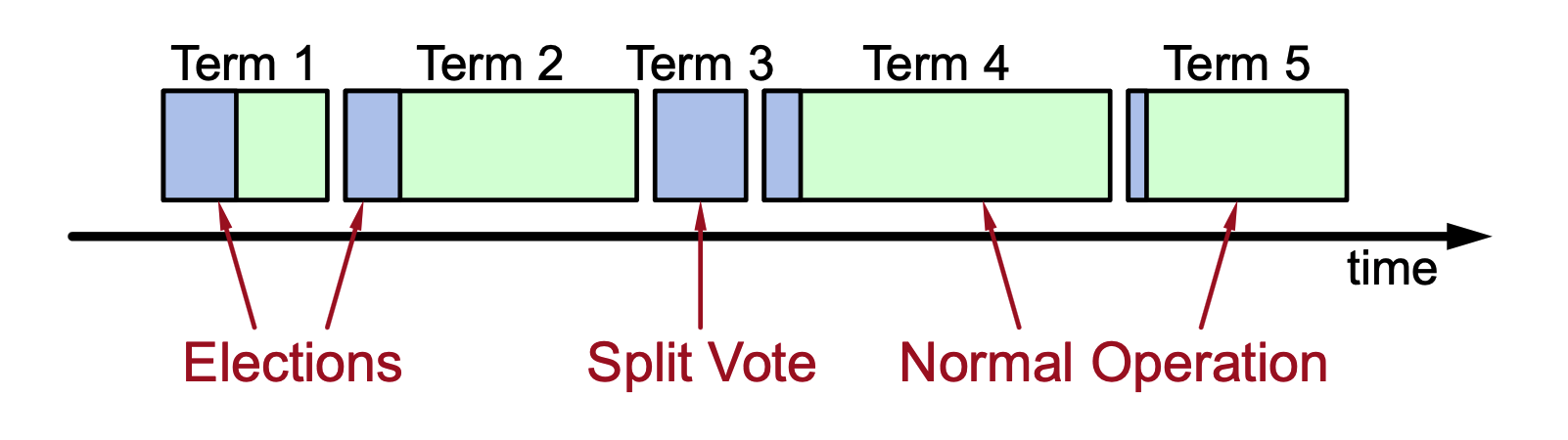
Time Division: Raft divides time into terms of arbitrary length. Each term begins with an election, and normal operations under a single leader.
-
Leader Authority: Each term has at most one leader. If an election results in a split vote, that term may have no leader.
- A new term begins whenever a new election starts. Each server keeps track of the current term number, which only increases over time.
-
A split vote happens when no candidate gets a majority of votes during an election.
What happens in Raft when split vote occurs?
- The election fails (no leader chosen).
- Each candidate waits for its election timeout again.
- A new term begins.
- Another election starts.
- Current Term: Every server maintains a
current termvalue to identify and discard obsolete information. - Heartbeats: Leaders must send empty
AppendEntriesRPCs (heartbeats) to maintain authority. If a follower's electionTimeout (100–500ms) elapses without receiving an RPC, it assumes the leader crashed and starts a new election.
Log Structure and Replication¶
- Log Entry: Each entry contains a log index, the term it was created in, and the command.
- Durability: Logs are stored on stable storage (disk) to survive crashes.
- Commitment: An entry is considered committed once it is stored on a majority of servers. Once committed, it is durable and will eventually be executed by all state machines.
Normal Operation Flow¶
- Client sends a command to the leader.
- Leader appends the command to its local log.
- Leader broadcasts
AppendEntriesRPCs to followers. - Followers accept the entry if and only if the logs match up until the index, like they check “Does my log match the leader up to prev_index and prev_term?”. Only after getting positive result they append the entry to their own logs and sends acknowledgement back to leader.
- Otherwise, followers reject the request. They have to fix the logs! It forces the leader to resend earlier entries.
- Once a majority respond (more than half the servers acknowledge), the leader commits the entry and notifies followers of committed entries to execute the command.
- Any server (leader or follower) executes commands only after they are committed.
- Leader passes command to its state machine, returns result to client
- Leader notifies followers of committed entries in subsequent
AppendEntriesRPCs- The leader does not send a separate “execute” message.
- Followers pass committed commands to their state machines
- Leader returns the result to the client.
Generally, after a majority replication, the leader commits the entry, executes it locally, replies to the client, and informs followers of the commit via the next AppendEntries RPC.
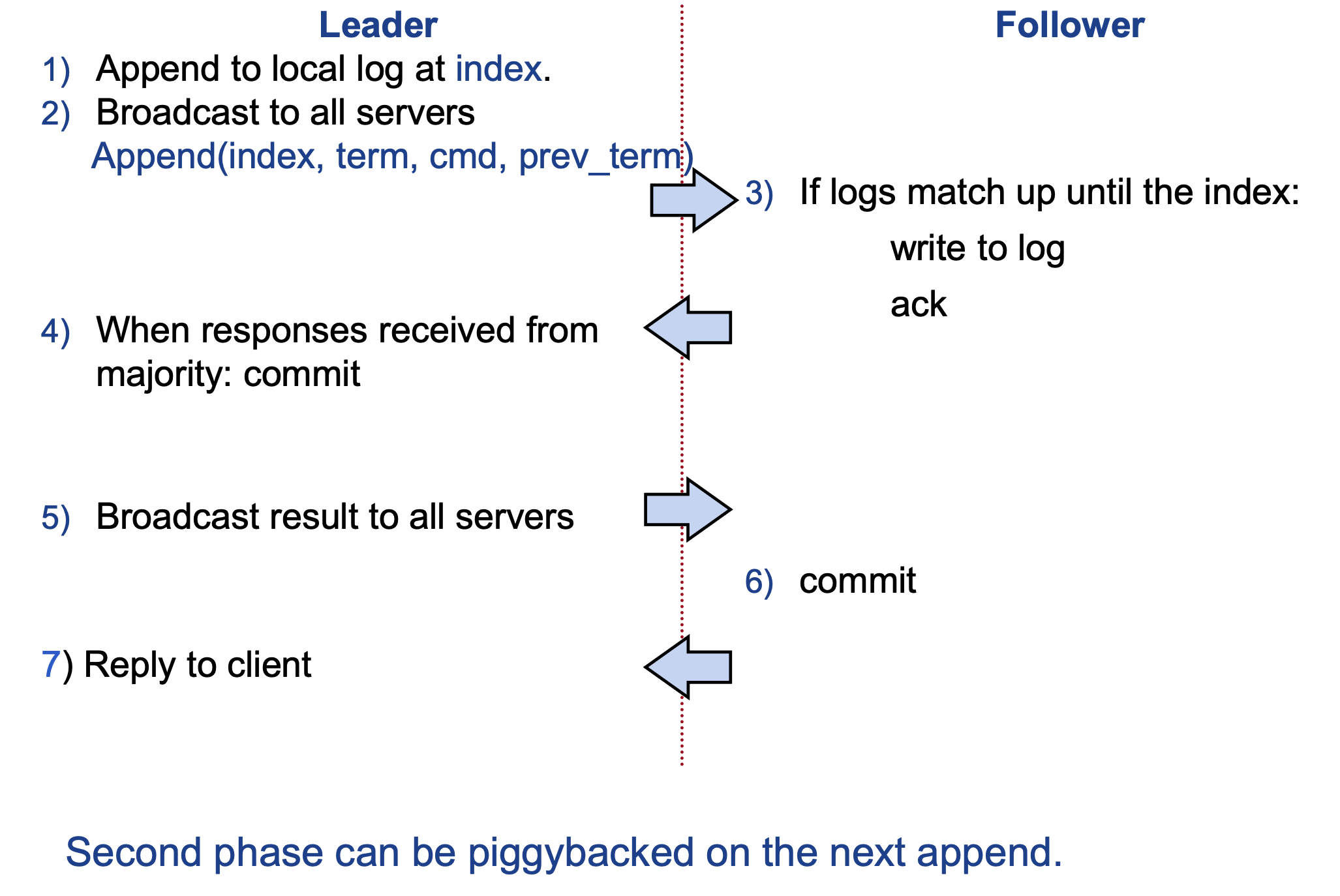
- Raft replicates commands in a log, not the system state. Each server stores the same ordered log of commands.
-
After a log entry is committed (replicated to a majority), each server applies it to its local state machine in order using
while lastApplied < commitIndex: lastApplied += 1 apply(log[lastApplied]) -
Because all servers execute the same commands in the same order, their state machines remain identical.
- If there are crashed or slow followers, leader retries RPCs until they succeed
Why send two messages to commit?
The first message replicates the log, the second tells followers the entry is committed and can be executed. Raft separates two things:
- Log replication
- Log commitment (execution)
This separation is necessary for safety.
Why not execute immediately?
Because the leader might crash before majority replication. For example,
Leader writes command
sends to only 1 follower
then crashes
Another server becomes leader that doesn’t have that command. If the follower had already executed the command, the system would become inconsistent.
So Raft rule:
replicate first
commit later
execute after commit
Log Consistency and Repair¶
- Coherency: If two entries on different servers have the same index and term, they are guaranteed to store the same command and have identical preceding entries.
- If a given entry is committed, all preceding entries are also committed.
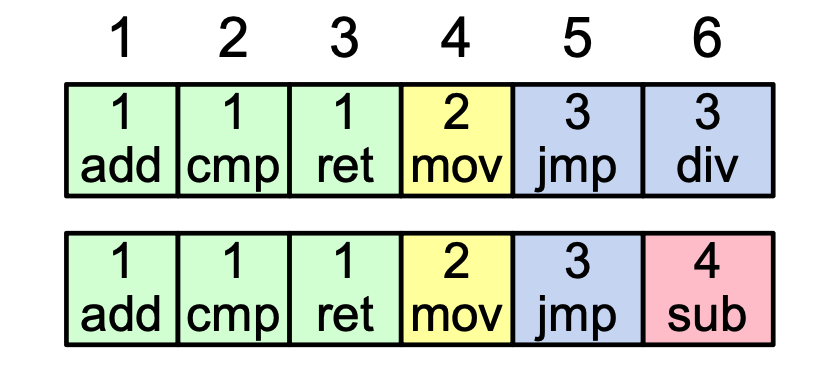
- Consistency Check: Every
AppendEntriesRPC includes the index, and term of the entry immediately preceding the new ones. A follower rejects the request if its log doesn't match this "induction step".- Follower must contain matching entry!
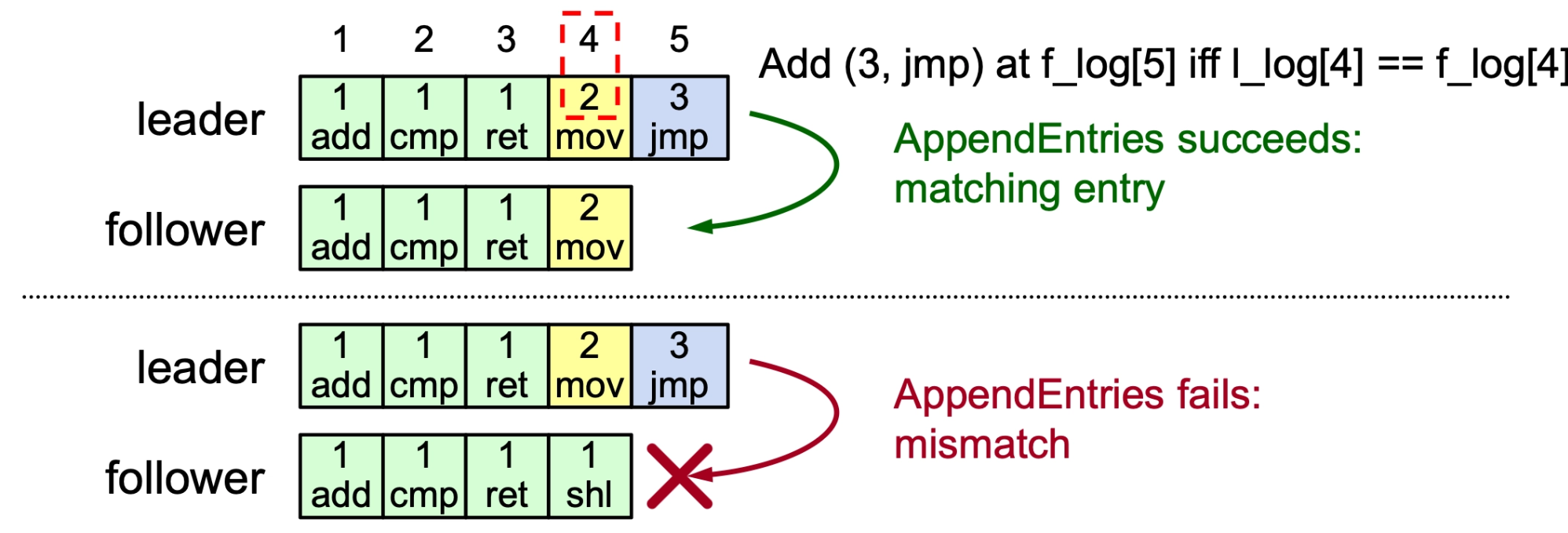
- Repairing Logs: When a check fails (often after a leader change), the leader decrements a
nextIndexfor that follower and retries until a match is found. It then deletes extraneous entries in the follower's log and fills in the missing ones from its own.- Leader keeps
nextIndexfor each follower:- It represents the index of the next log entry the leader should send to that follower.
nextIndexstarts at \(\text{leaderLastIndex} + 1\) because the leader initially assumes followers are fully up-to-date, and only moves backward if that assumption is wrong.
- Leader keeps
Raft Consensus: Election and Safety Rules¶
Election Mechanism¶
- Server States: At any time, a server is a Follower (passive, issues no RPCs but responds to incoming RPCs), Candidate (seeking election), or Leader (handling all client interactions, log replications).
- Normal operation has \(1\) leader, \(N-1\) followers.
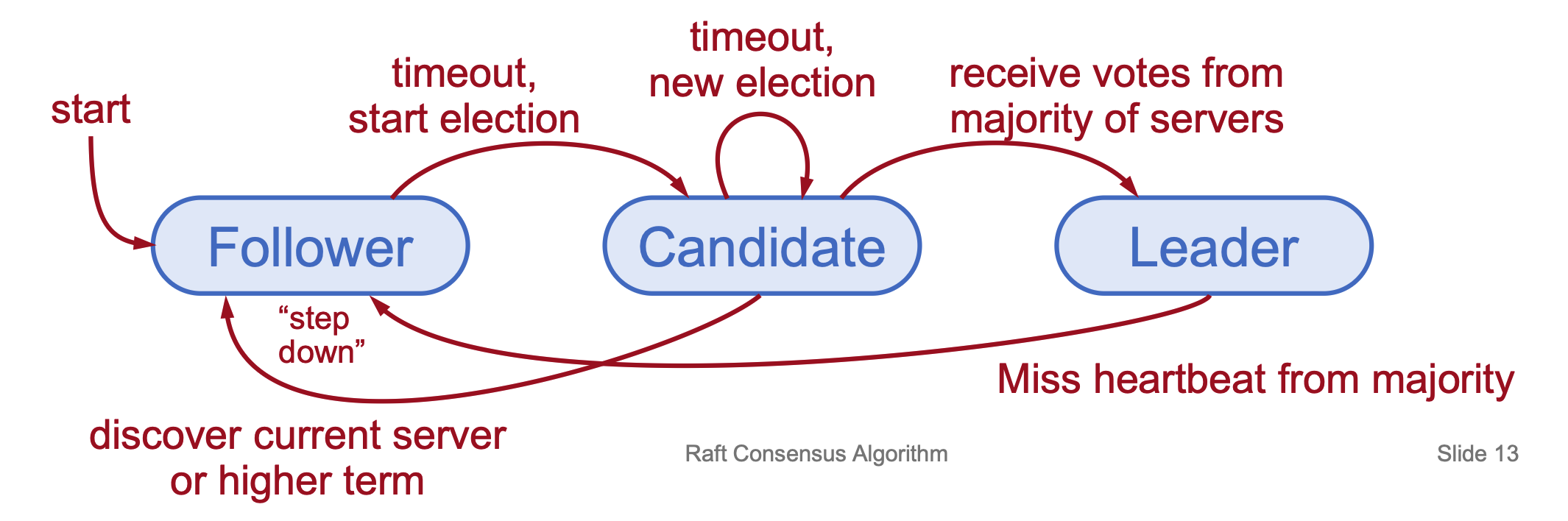
- Election Basics: A server triggers an election by incrementing its current term, changing to Candidate state, and voting for itself. It sends
RequestVoteRPCs to all other servers. - Election Outcomes:
- Win: Receives votes from a majority, becomes leader, and starts sending heartbeats.
- Step Down: Receives an RPC from a valid leader and returns to follower state.
- No Winner: If an election timeout elapses with no winner, the candidate increments the term and starts again.
-
Liveness: To avoid split votes where no one wins, Raft uses randomized election timeouts (e.g., [\(T, 2T\)]), ensuring one server usually wakes up and wins before others.
- Liveness goal: Raft must eventually elect a leader. To prevent elections from getting stuck due to split votes, servers wait random amounts of time before starting an election.
- Randomized election timeout: Each server chooses a random timeout in a range \([T, 2T]\) before becoming a candidate. Because these timeouts differ, one server usually starts the election earlier and gathers votes before others start competing.
- What is \(T\): \(T\) is the base election timeout value (a minimum waiting time). Servers pick a random timeout between \(T\) and \(2T\) to reduce the chance that multiple servers start elections simultaneously.
- Works well if \(T >>\) broadcast time
- Broadcast time = the time it takes for a server to send an RPC to all other servers and receive their responses.
Simply,
- Each server sets a random election timeout. When it hasn’t heard from a leader (via heartbeats) for that amount of time, it starts an election.
- Because the timeout is randomly chosen in a range like \([T, 2T]\), servers will very likely start elections at different times.
- The server whose timer expires first becomes a candidate, requests votes, and usually gets a majority before others’ timers expire, preventing a split vote.
Leader Changes¶
In a consensus protocol like Raft, the transition to a new leader requires reconciling potentially inconsistent logs across different servers caused by previous crashes.
Initial State of the New Term
- Partially Replicated Entries: The previous leader may have crashed before fully replicating all entries to a majority of the cluster.
- Seamless Transition: The new leader does not perform a special "cleanup" phase; it simply begins normal operations.
- The Leader’s Log is "The Truth": The protocol operates on the principle that the leader's log is the authoritative record. Any inconsistencies in follower logs must be resolved to match the leader's.
- Eventual Consistency: Through regular heartbeats and log replication RPCs, the leader will eventually force the followers' logs to become identical to its own.
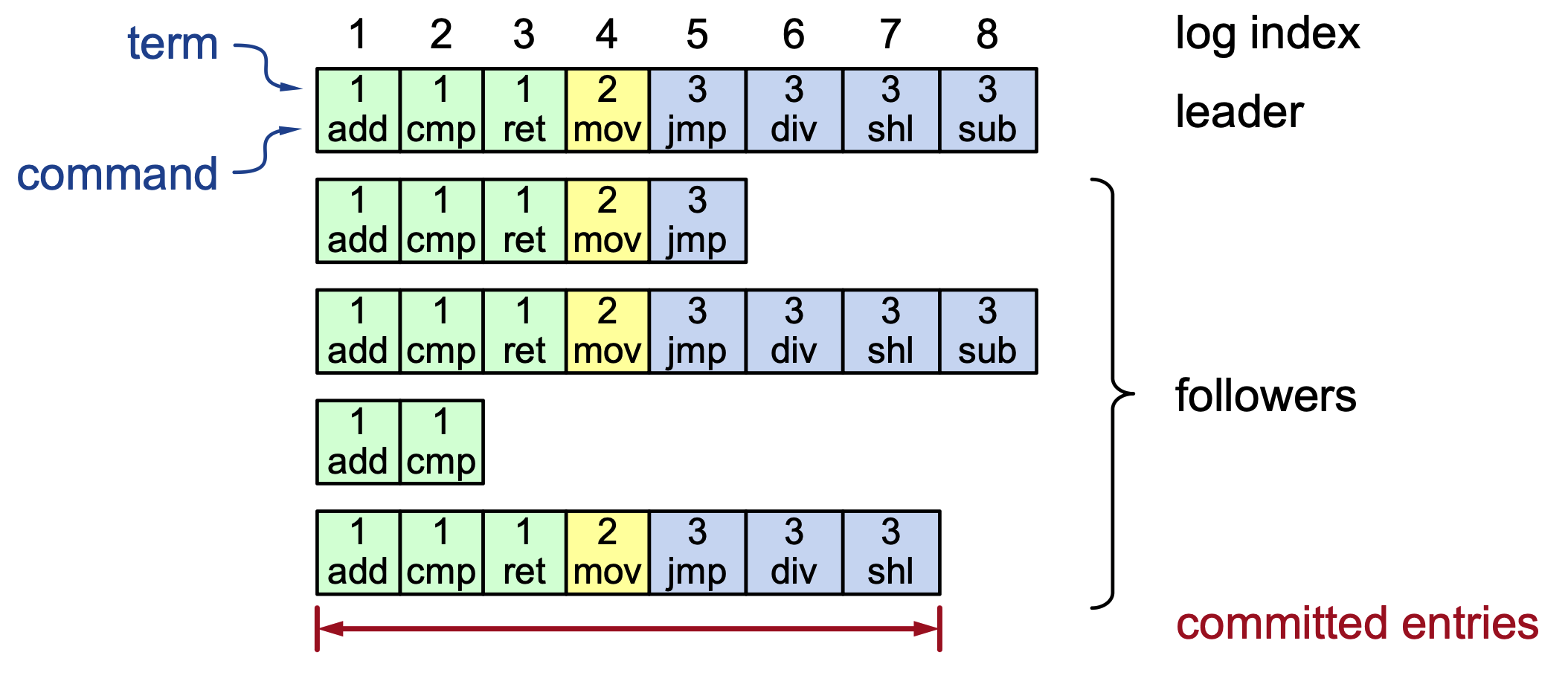
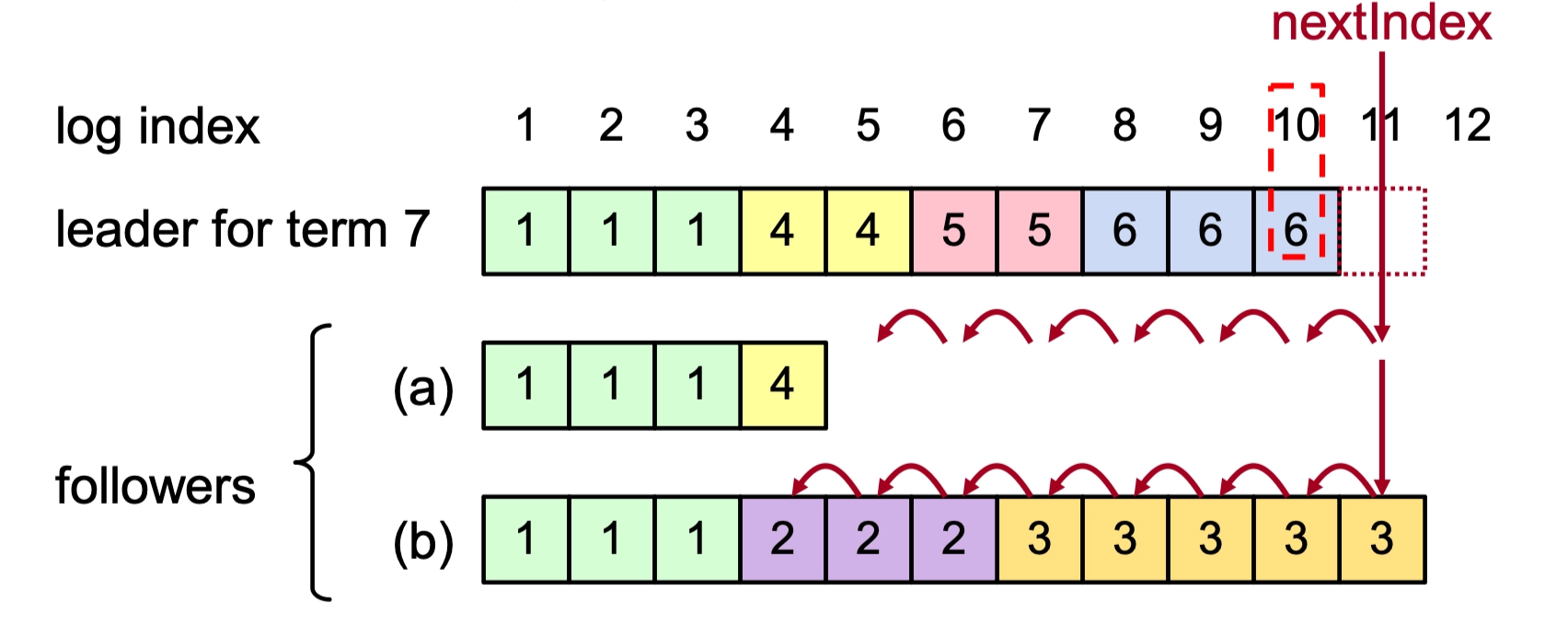
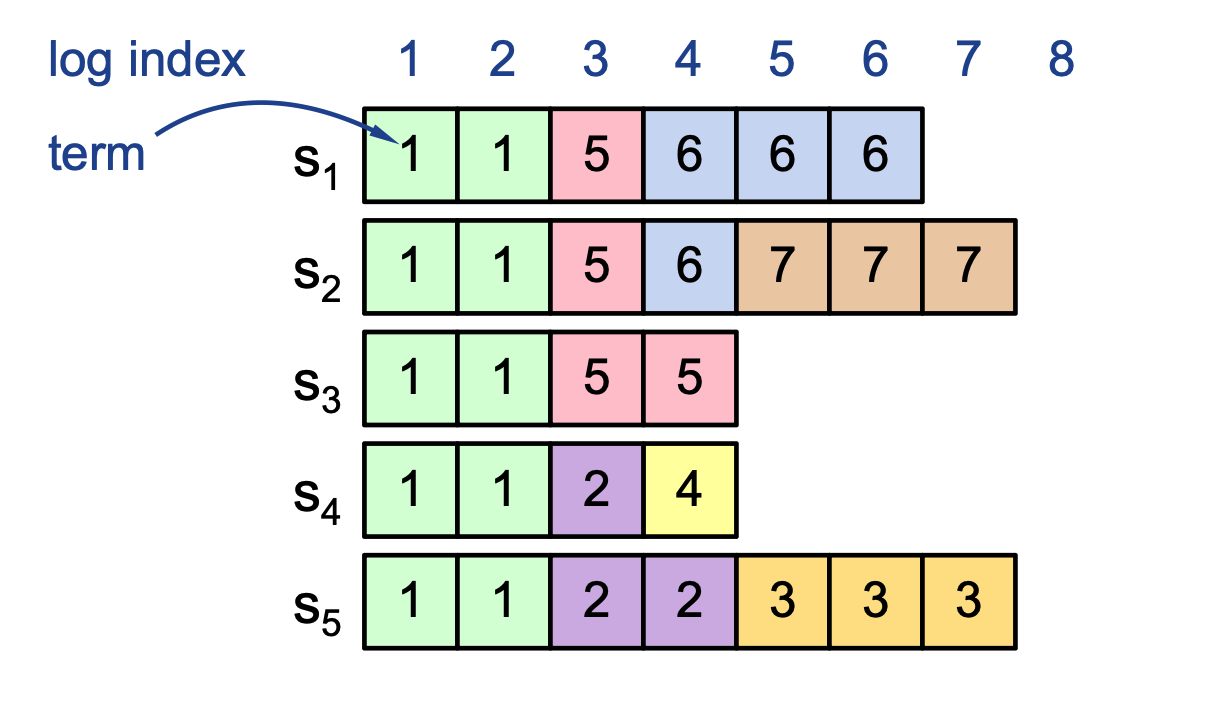
Log Inconsistencies and Crashes
Multiple crashes of leaders and followers over different terms can leave complex, extraneous log entries that vary across the cluster.
- Log Index: The position of the entry in the log (e.g., 1 through 8).
- Term Number: The specific term in which the entry was created (indicated by the number inside the boxes).
-
Example Scenario:
- Servers \(S_1\) through \(S_5\) may have conflicting entries at the same index due to different leaders being active in terms 2, 3, 4, 5, 6, and 7.
- Some servers might be missing entries (like \(S_3\) and \(S_4\)), while others have extra entries from terms that were never committed (like \(S_2\) and \(S_5\)).
Safety Requirements¶
-
The Core Rule: Once a log entry is applied to a state machine, no other state machine must ever apply a different value for that same log index.
- If a leader has decided that a log entry is committed, that entry will be present in the logs of all future leaders.
- Leaders never overwrite entries in their logs.
- Only entries in the leader’s log can be committed.
- Entries must be committed before applying to the state machine.

-
Election Safety: At most one winner per term is allowed. Servers persist their single vote per term to disk to prevent double-voting.

Picking the Best Leader¶
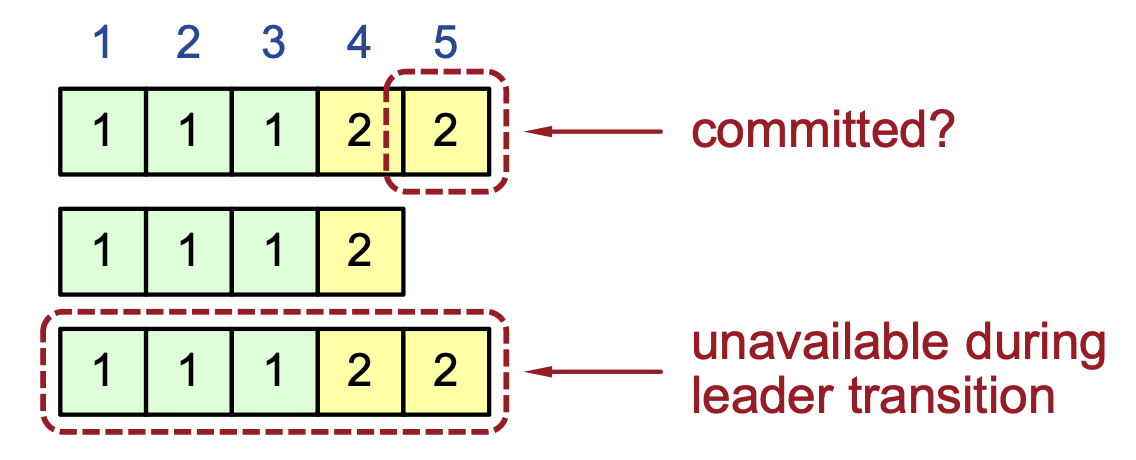
-
Followers cannot determine which entries are committed during leader changes.
-
A log entry is committed only when it is replicated on a majority of servers, but followers do not know the replication status across the cluster once the leader crashes. Therefore, during an election they cannot locally determine whether the last entries in their log are committed.
-
-
Raft solves this by electing the server with the most up-to-date log.
- When voting, a server refuses a candidate if its own log is more up-to-date using below formula under Leader Completeness.
- This guarantees that any committed entry (which must exist on a majority of servers) will also exist on the newly elected leader’s log, because at least one voter that already has that entry would refuse to vote for a candidate missing it.
- Leader Completeness: Voters (Voting server \(V\)) deny a vote if their own log is "more complete" than the candidate \(C\)'s. This is defined by comparing the term and index of the last log entry:
- The elected leader must have the most complete log.
-
A follower refuses to vote if its log is more complete.
\[ \text{(lastTerm}_V > \text{lastTerm}_C\text{)} \;||\; \text{(lastTerm}_V == \text{lastTerm}_C \;\&\&\; \text{lastIndex}_V > \text{lastIndex}_C\text{)} \]
Committing Entry from Current Term¶
- Important commit rule for earlier-term entries:
- A leader cannot conclude that entries from previous terms are committed merely because they appear on a majority of servers.
- Instead, once the leader successfully replicates an entry from its current term to a majority, all preceding log entries (including those from earlier terms) become committed.
- Committing a current-term entry forces all future leaders to contain it.
- Majority replication alone is not enough for older-term entries.
- Must first commit a current-term entry.
- Then earlier entries become safely committed.
-
Intuition
- Elections guarantee the new leader already contains all committed entries.
- Replicating a current-term entry establishes a safe point that confirms earlier entries must also be preserved.
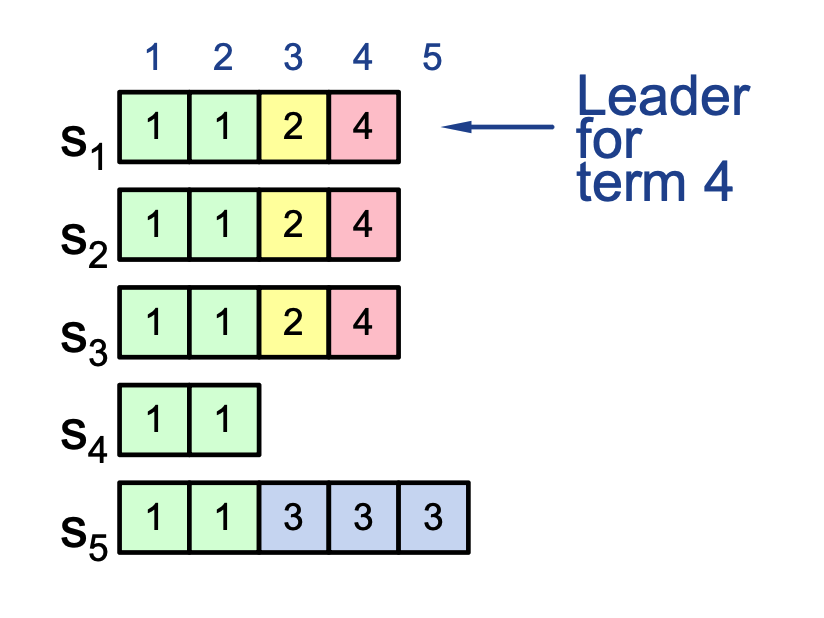
The leader should not try to finish committing an entry from an earlier term.
New Commitment Rule¶
For a leader to decide an entry is committed,
- Majority replication: The log entry must be stored on a majority of servers.
- Current-term confirmation: The leader must also replicate at least one entry from its current term to a majority.
- Safe commit: Once this current-term entry is replicated on a majority, the leader can safely consider that entry and all preceding entries committed.
Combination of election rules and commitment rules makes Raft safe
Client Protocol¶
- Communication: Clients send commands to the leader. If the leader is unknown, they contact any server, which redirects them to the current leader if it is not the leader.
- Response: The leader does not respond to the client until the command has been logged, committed, and executed by leader’s state machine.
- Retries: If a request times out (e.g., the leader crashes), the client reissues the command to another server until it reaches the new leader.
- Client sends request to a server
- If timeout → client retries (to same or another server)
- If server is not leader → it redirects to leader
- I guess the follower won’t act as a proxy but tell the client who is the leader or leader unknown instead of forwarding the request?
- Eventually → client reaches the current leader and request succeeds
Configuration Changes in Distributed Systems¶
Managing configuration changes (adding/removing servers, changing IDs/addresses) is a critical task in distributed systems to maintain availability and data integrity.
Challenges of Manual or Direct Transitions¶
- Dynamic Needs: Mechanisms must support replacing failed machines or changing the degree of replication without stopping the system.
-
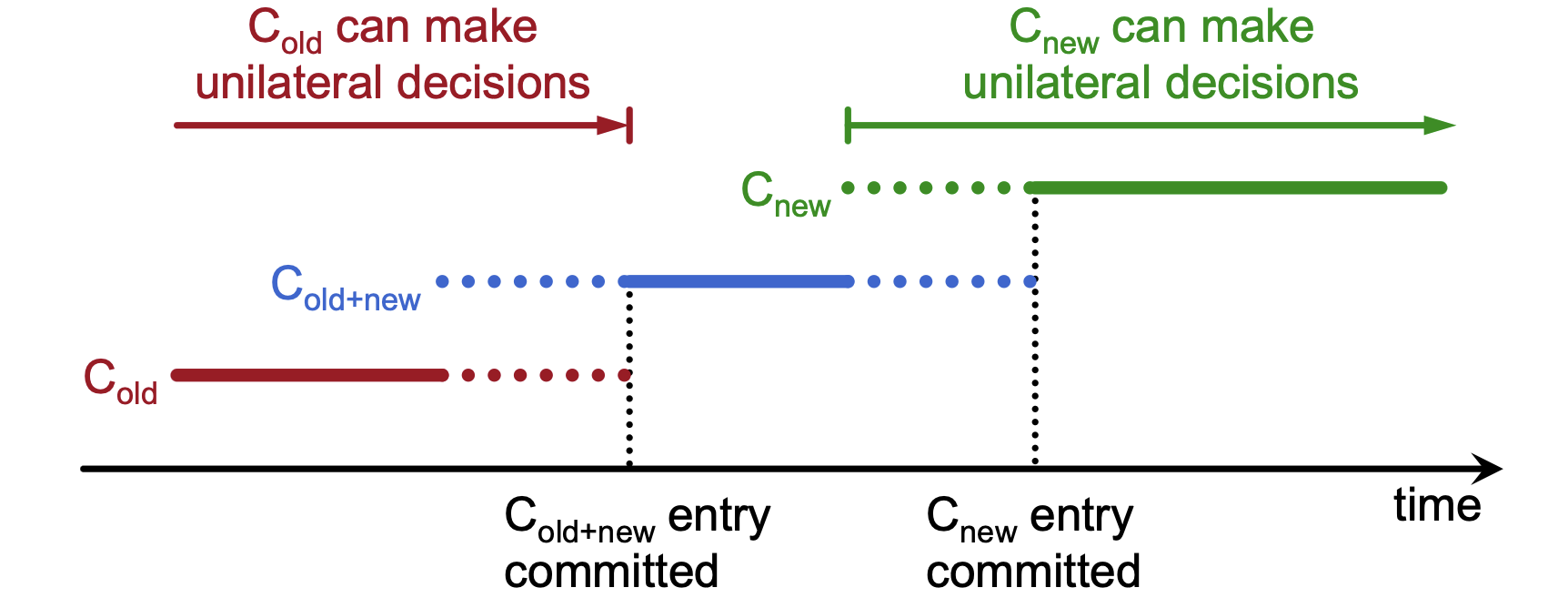
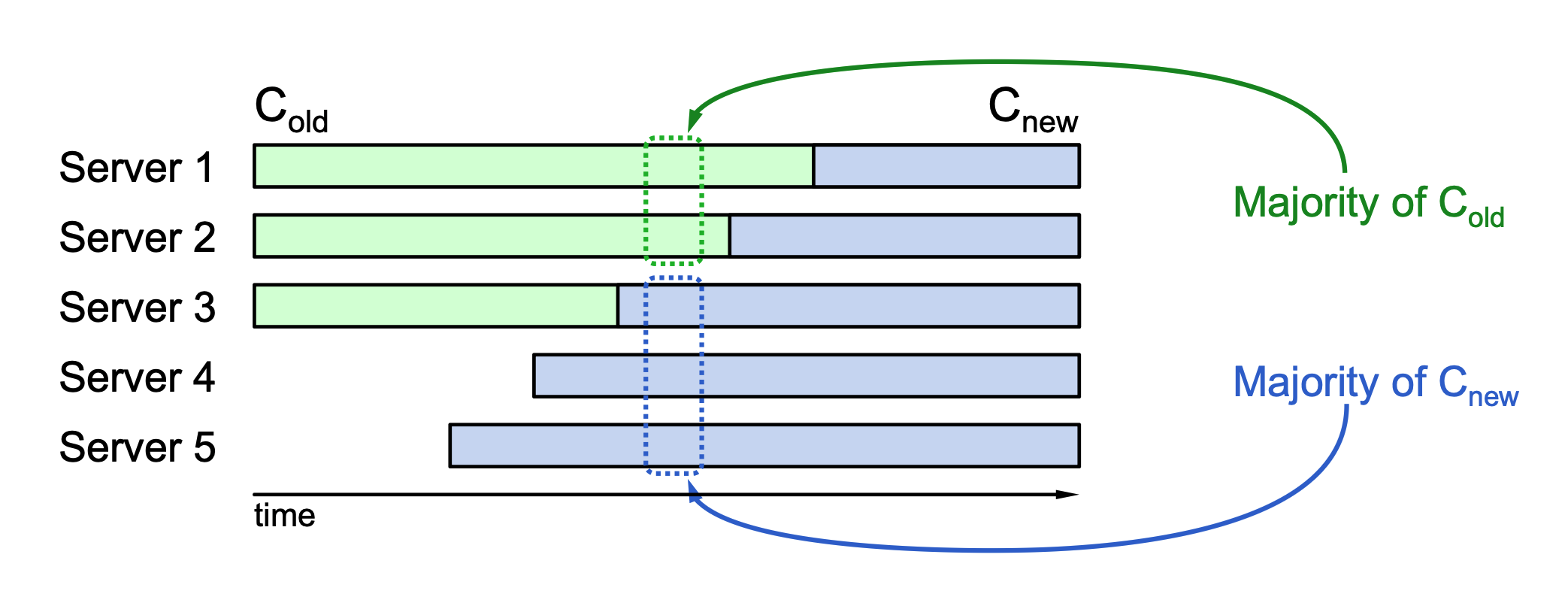
Safety Risks: A direct switch from an old configuration (\(C_{old}\)) to a new one (\(C_{new}\)) can result in conflicting majorities.
-
Split Brain Scenario: Because servers do not all switch at the exact same instant, two independent majorities can exist simultaneously—one under \(C_{old}\) rules and one under \(C_{new}\) rules—allowing both to make conflicting unilateral decisions.
The Raft Solution: Joint Consensus¶
To ensure a safe transition, the Raft algorithm uses a 2-phase approach known as joint consensus.
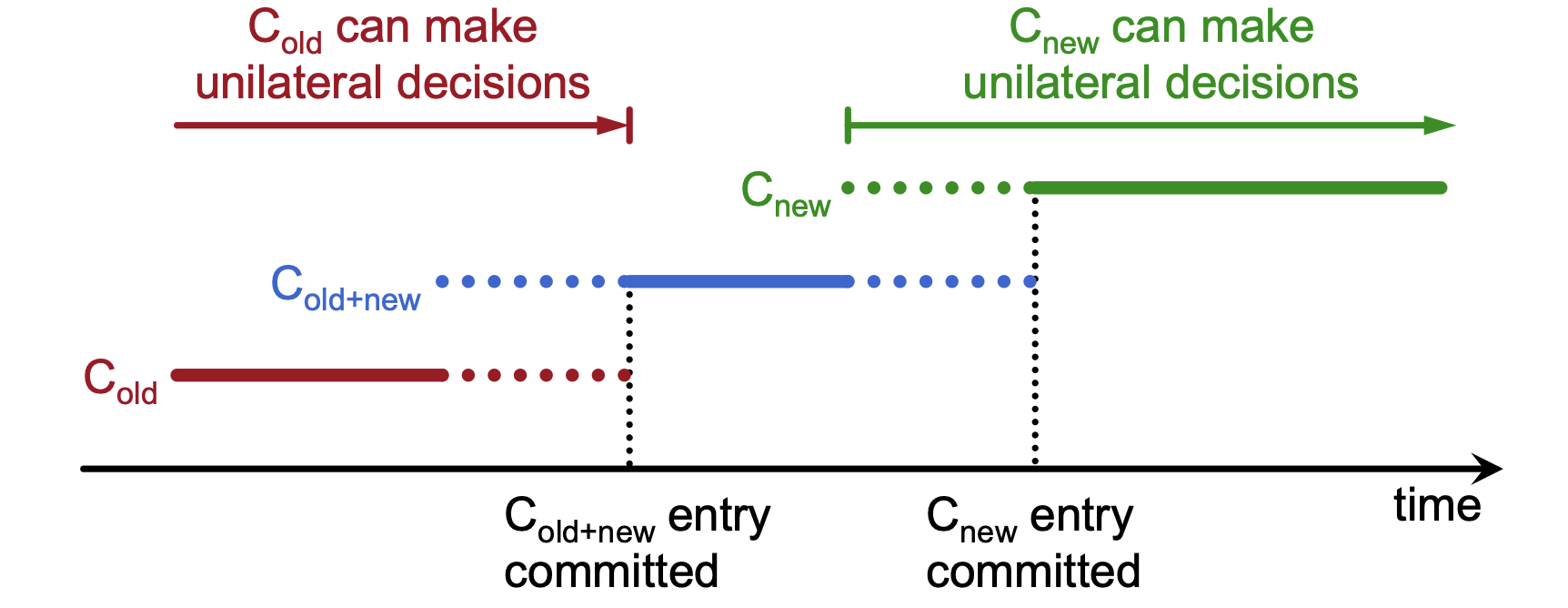
Intermediate Phase (\(C_{old+new}\))¶
- Joint Governance: During this phase, the system uses a configuration that requires a majority from both the old configuration and the new configuration for elections and commitment.
- Log-Based Implementation: The configuration change is treated as a log entry; servers apply it immediately upon receipt, whether or not it is yet committed.
Final Phase (\(C_{new}\))¶
- Commitment: Once the joint consensus entry is successfully committed, the leader begins replicating the log entry for the final configuration (\(C_{new}\)).
- Successfully committed means a majority of both groups have it
- Safe Handover:
- Before joint consensus, \(C_{old}\) can make decisions unilaterally.
- During joint consensus, neither can act without the other.
- After \(C_{new}\) entry is committed, the new configuration can make decisions unilaterally.