Google File System¶
Goals, Architecture, and Operations¶
GFS Goals and Assumptions¶
The Google File System was designed to provide high-throughput, scalable, and reliable storage for Google’s massive data processing needs.
- Failure as a Norm: Component failures (disk, node, network) are common and must be handled gracefully.
- Large Files: Files are typically measured in hundreds of Megabytes to many Gigabytes.
- Workload Characteristics:
- Primarily sequential access (rarely random).
- Writes are mostly appends rather than overwriting existing data.
- Priority: High sustained bandwidth is more critical than low access latency.
- It’s more important to move a large amount of data continuously (high throughput) than to respond very quickly to a single request (low latency).
GFS Interface and Data Chunking¶
GFS provides a familiar file system interface but is optimized for large-scale operations.
- Standard Operations: Create, Delete, Open, Close, Read, Write.
- Open – open a file and get its handle
- Close – close an open file specified by a handle
- Append: A specialized operation to write data to the end of a file.
- Chunking: Files are divided into fixed-size chunks of 64MB. Each chunk has a unique 64-bit immutable chunk handle.
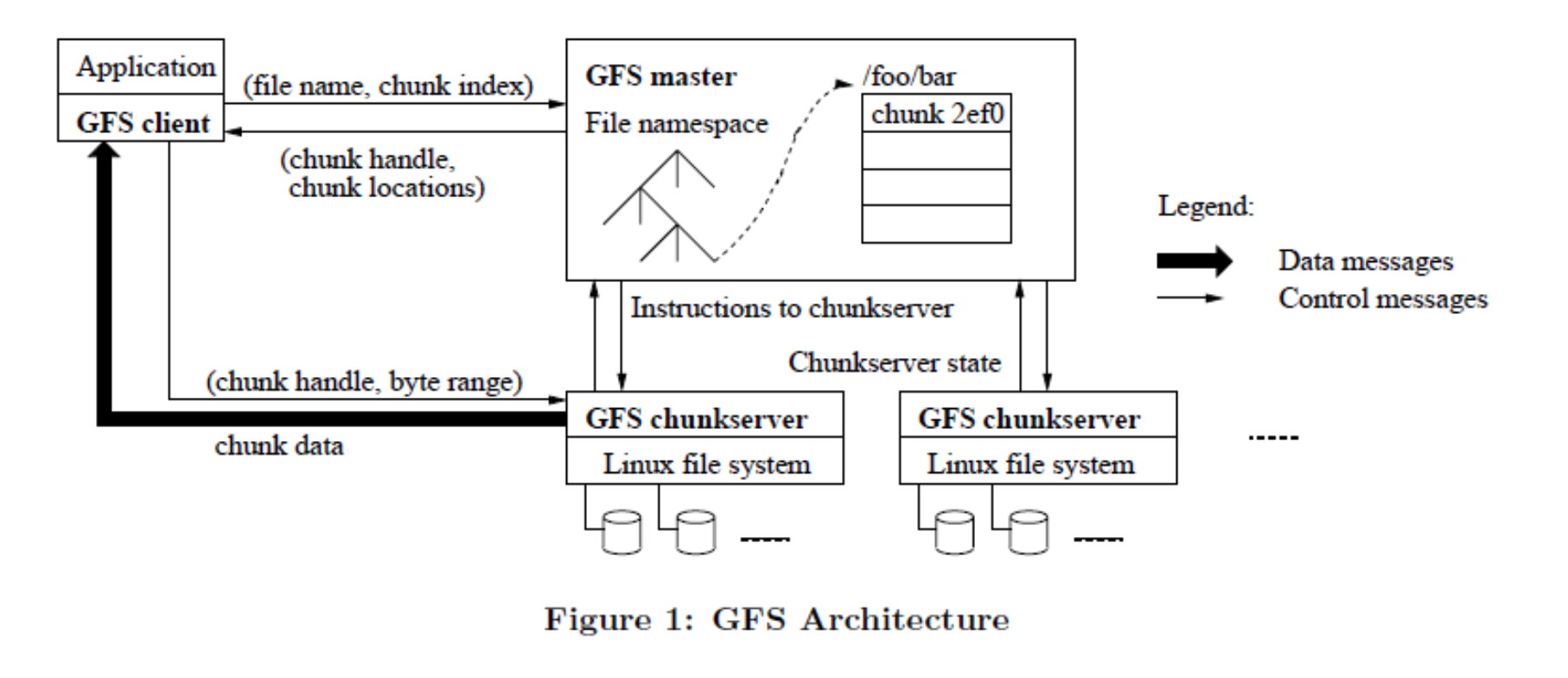
GFS Architecture¶
The system consists of a single Master and multiple Chunkservers.
- GFS Master:
- Maintains all file system metadata.
- Manages system-wide activities (garbage collection, chunk migration).
- Communicates with chunkservers via Heartbeat messages to give instructions and collect state.
- GFS Chunkservers: Store chunks on local Linux file systems as regular files.
- GFS Client: Communicates with the Master for metadata but interacts directly with Chunkservers for data transfers.
- For example, locations = {Server A, Server B, Server C}
Metadata Management¶
The Master node maintains three major types of metadata:
- File Namespace: Hierarchical structure of files (persisted).
- File-to-Chunk Mapping: Which chunks belong to which file (persisted).
- Chunk Replica Locations: Which chunkservers hold copies of which chunks (not persisted; built at startup by polling chunkservers).
Metadata changes are recorded in an Operation Log and periodically checkpointed to minimize recovery time. The Master also performs periodic scans for:
- Replication checking (finding under-replicated chunks).
- Garbage collection of deleted files.
- Load balancing across chunkservers.
- Distribute work (reads/writes/storage) evenly across all servers.
Consistency Model¶
GFS follows a relaxed consistency model to maintain high performance.
- Namespace Mutations: (e.g., file creation) Are atomic and serialized by the Master.
- Serialized = executed one at a time, in a strict order
- Data Consistency Definitions:
- Consistent: All clients see the same data regardless of which replica they read.
- Defined: Consistent, and clients see the mutation in its entirety (not interspersed with other writes).
- Interspersed = mixed together / overlapping pieces
File Region States After Mutation¶
| Mutation Type | Success | Failure |
|---|---|---|
| Serial Write | Defined | Inconsistent |
| Concurrent Write | Consistent but Undefined | Inconsistent |
| Record Append | Defined interspersed with Inconsistent | Inconsistent |
Let’s say we have S1, S2, S3 replicas. If write to S1 and S2 succeeds but S3 fails, the write fails with error, which means the file state is inconsistent.
If concurrent write and the data is on 2 different chunks, first chunk may commit request from client 2 while second chunk commits request from client 1.
Use checksum to detect corruption.
Mutation Operations: Write and Append¶
The Write Operation¶
Writes are serialized to maintain order for all updates across replicas to a file. The Master grants a lease to one replica, designated as the Primary.
- Phase I (Metadata): Client asks the Master which chunkserver holds the lease (primary) and the locations of other replicas.
- Phase II (Data Transfer): Client pushes data to all replicas. They store it in a temporary buffer (memory).
- This is a chain operation. The client sends data to the primary first, and the primary will transfer the data to the next replica etc.. For example, Client → S1 → S2 → S3 where S1 is the primary (pipeline).
- All replicas receive the data BEFORE writing
- Phase III (Commit): Once all replicas acknowledge receiving the data, the client sends a write/commit request to the primary. The primary assigns a serial number to the update and instructs secondaries to apply the write in that specific order.
The Append Operation¶
Appends follow the same logic as writes but the primary determines the offset where the data will be written. It has different phase 3.
-
Chunk Boundary Check: If an append exceeds the 64MB chunk size, the primary pads the current chunk, tells the client to retry on the next (new) chunk, and the operation fails. Otherwise, append the data to the chunk and notify the secondary replicas.
When a client tries to append data and there isn’t enough space left in the current chunk:
- The system does NOT partially fill the chunk with your data
- Instead, it fills the remaining unused space with dummy bytes (padding)
- usually zeros or undefined filler
- At-least-once Semantics: Because GFS retries failed appends, data might be duplicated on some replicas.
- If a record append fails at any replica, the client retries. Some machines saw both attempts, some only saw one.
- The primary replica determines the offset for a record append. If an append partially succeeds and is retried (client sees it as failure), the primary may append the record again at a new offset, resulting in duplicate records on some replicas. Other replicas may contain only one copy of the record, leading to divergence across replicas rather than gaps in the file.
Handling Data Corruption and Duplicates¶
Since GFS allows for "at-least-once" append semantics and potential inconsistencies:
- Checksums: Chunkservers use checksums to detect data corruption.
- Application Responsibility: Applications must be designed to handle duplicates and padding. This is done by including unique identifiers and record information within the written data so the application can validate records during the read process.
- Use sequence number and
previous_callstable, and if the entry exists in the table, don’t double execute it.
- Use sequence number and