Dynamo¶
Consistency and Amazon Dynamo¶
Eventual Consistency¶
Eventual consistency is a consistency model that trades off immediate consistency for higher availability and performance. It is ideal for applications that can tolerate temporary periods of inconsistent values.
- Core Principle: If no new updates are made to a specific data item, eventually all accesses to that item will return the last updated value.
- Convergent Behavior: In the absence of further updates, all replicas will eventually converge to identical copies.
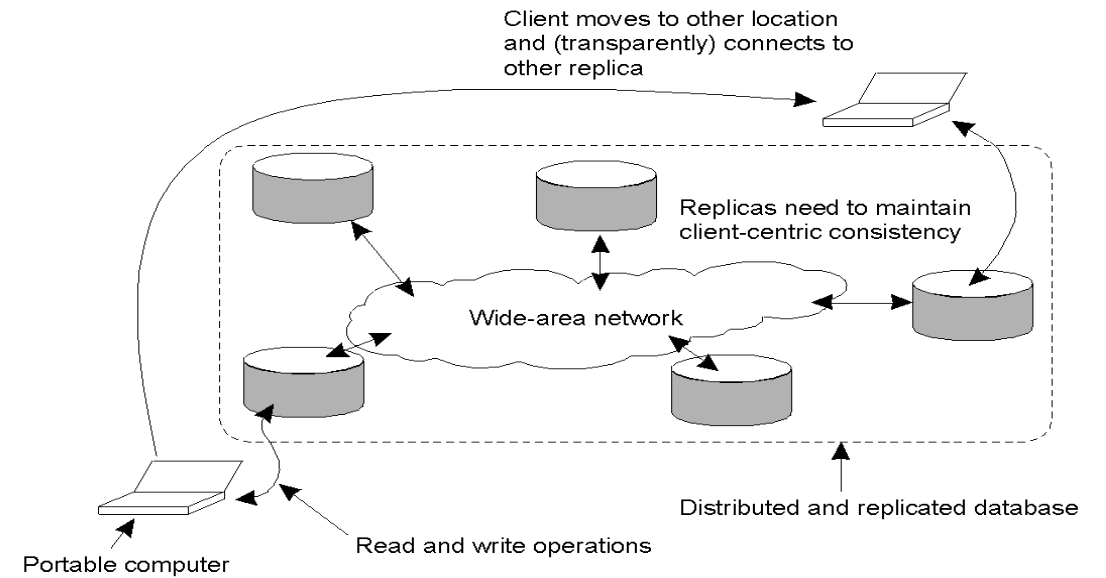
Client Centric Consistency¶
This is a relaxed form of consistency focused on providing guarantees for a single client accessing a data store, even if that client moves between different replicas.
- The Mobility Problem: Consistency is easy if a user always hits the same replica. However, it becomes problematic if a user moves locations and connects to a different, potentially lagging, replica.
Types of Client Centric Consistency¶
- Monotonic Reads: If a process reads the value of data item \(x\), any successive read on \(x\) by that process will return that same value or a more recent value.
- Monotonic Writes: A write operation by a process on data item \(x\) is completed before any successive write operation on \(x\) by the same process.
- Read Your Writes: The effect of a write operation by a process on data item \(x\) will always be seen by a successive read operation on \(x\) by the same process.
- Pure Eventual: A read operation of a variable \(x\) can return any previous value of \(x\) (the most relaxed form).
- It only guarantees system eventually converges if writes stop.
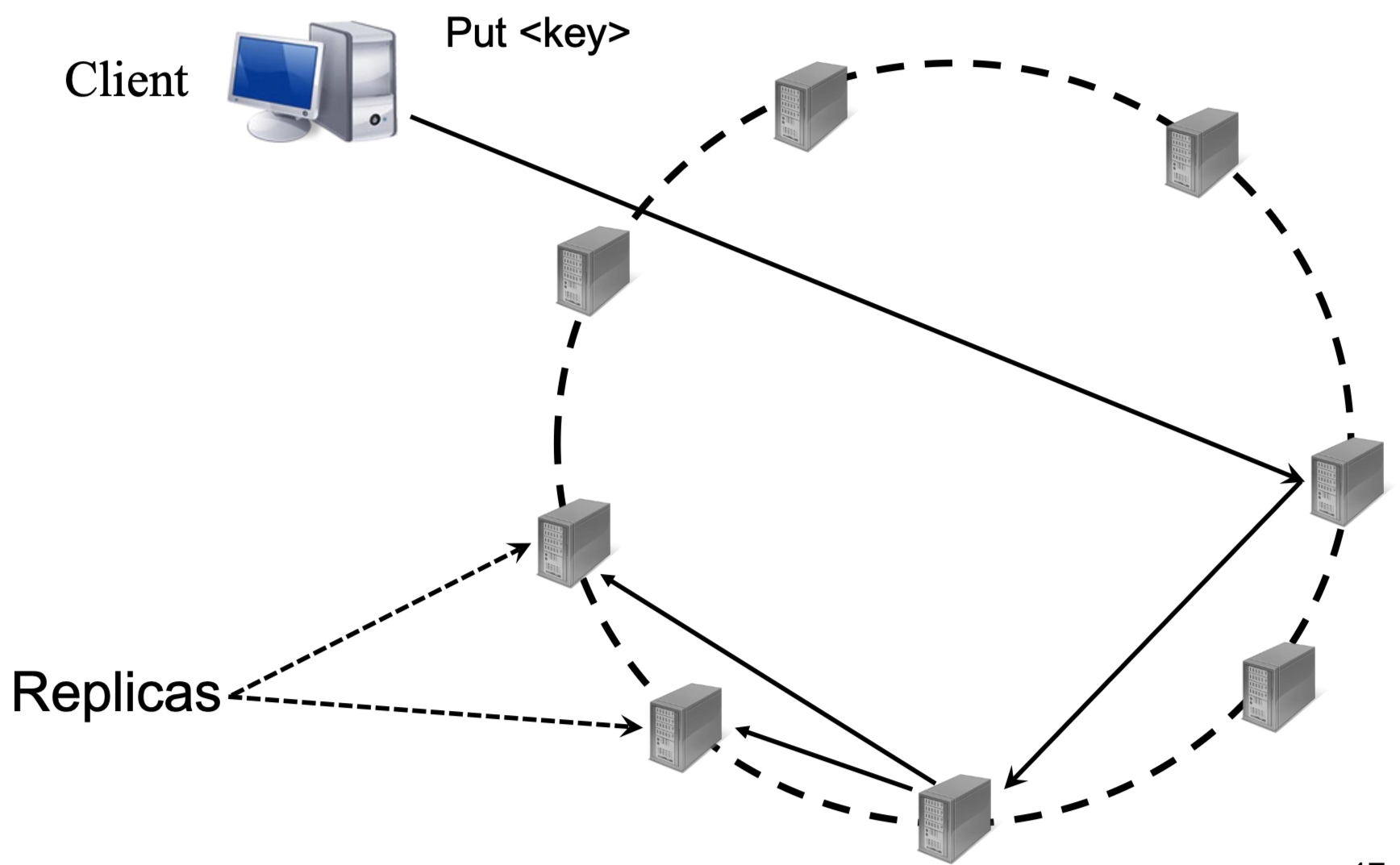
Key Value Storage¶
Key-Value (KV) storage is a critical component in modern data centers. It relies on two basic operations:
- Put(key, value): Stores a value under a specific key.
- Get(key): Retrieves the value associated with a key.
Common examples include Amazon Dynamo, Cassandra, Amazon S3, Riak, and OpenStack Swift.
Amazon Dynamo Goals¶
The design of Amazon Dynamo is driven by specific architectural goals:
- High Availability: Availability is more important than consistency; the system must always be writable.
- Scalability: The system must scale easily as demand grows.
- Failure as Norm: The system must handle frequent node failures.
- Tail Latency: Focus on the 99.9th percentile (e.g., latency below 300ms for 500 requests per second).
- Heterogeneity: Ability to support nodes with different hardware capabilities.
Consistent Hashing and Routing¶
Dynamo uses Consistent Hashing to distribute data across a cluster of nodes.
- The Ring: All possible hash values are represented as a circular space (a ring).
- Node Placement: Replicas (nodes) are assigned positions on this ring based on their hashed IP addresses.
- Full Membership Model: Every node knows the hash range of every other node. This allows for \(O(1)\) routing, meaning any node can forward a request directly to the correct destination.
Membership and Gossip Protocol¶
To maintain the "ring" and know which nodes are active, Dynamo uses a decentralized membership management system.
Membership = the list of all nodes in the system + their status
- Manual Entry: Administrators manually add or remove nodes to the system.
- Gossip-Based Protocol: Nodes use an "epidemic" protocol to propagate membership information.
- The Process: A node picks another node at random and exchanges membership information. Any inconsistencies are resolved, and the ring eventually converges on a consistent state.
Quorum Based Consistency Model¶
To manage replication and consistency, Dynamo uses a Quorum (\(N, W, R\)) system:
- \(N\): The number of replicas.
- \(W\): The number of nodes that must confirm a write.
- \(R\): The number of nodes that must confirm a read.
Quorum Rules¶
- \(R + W > N\): This ensures that the read set and write set overlap, guaranteeing that a read will see the most recent write.
- \(W > \frac{N}{2}\): This guarantees that two simultaneous writes will overlap, preventing conflicting updates.
Common configurations include \((3, 2, 2)\) for a balanced approach, or \((5, 4, 2)\) and \((5, 5, 1)\) depending on whether the system prioritizes read or write performance.
Dynamo Strategy and Conflict Resolution¶
CAP Theorem¶
The CAP theorem states that in a distributed system, it is impossible to simultaneously provide more than two out of the following three guarantees: Consistency, Availability, and Partition Tolerance.
- Trade-off: In the presence of a network partition, a system must choose between sequential consistency and 100% availability.
Dynamo Strategy¶
Amazon Dynamo prioritizes availability over consistency. This design choice ensures the system remains "always writable," which is a critical requirement for retail operations.
Conflict Resolution¶
Since Dynamo allows concurrent writes to ensure availability, data conflicts can occur.
- When to resolve? Conflicts are resolved during read operations rather than write operations.
- Who resolves them? Dynamo uses application-informed conflict resolution. This means the storage layer informs the application of the conflict, and the application logic (which has better context) performs the reconciliation.
Dynamo API and Object Mutability¶
The Dynamo interface is simplified to handle versioned data.
- Get(key): Returns a list of objects along with their associated contexts.
- Put(key, context, object): Stores an object. The context includes the object version and metadata like the vector clock.
- Immutability: Objects in Dynamo are treated as immutable. Instead of updating an existing object, the system rewrites a new version of the object with an updated context.
Dynamo Operations Detail¶
Put Operation¶
- A Coordinator node receives the put request.
- The coordinator adds/updates the vector clock for the version.
- The coordinator is the node who owns the hash range
- The data is written to local storage.
- The request is sent to \(N-1\) other nodes (replicas).
- \(N\) is the number of replicas, not the number of nodes on the ring! The coordinator is one of the replicas, thats’s why we sent to \(N-1\) nodes.
- These nodes are the next \(N−1\) nodes clockwise on the consistent hashing ring (preference list)
- If \(W-1\) nodes respond, the write is considered successful.
Vector Clocks: A list of
<node, sequence #>pairs for every node that has updated a specific key. This serves as the system's "memory" of the update history.
Get Operation¶
- A coordinator receives the get request.
- The request is sent to \(N-1\) nodes.
- If \(R-1\) nodes respond, the get is successful.
- The coordinator returns all divergent versions found from those \(R-1\) nodes to the client.
- The client consolidates the divergent versions and performs a
Putto save the consolidated version back to the system.
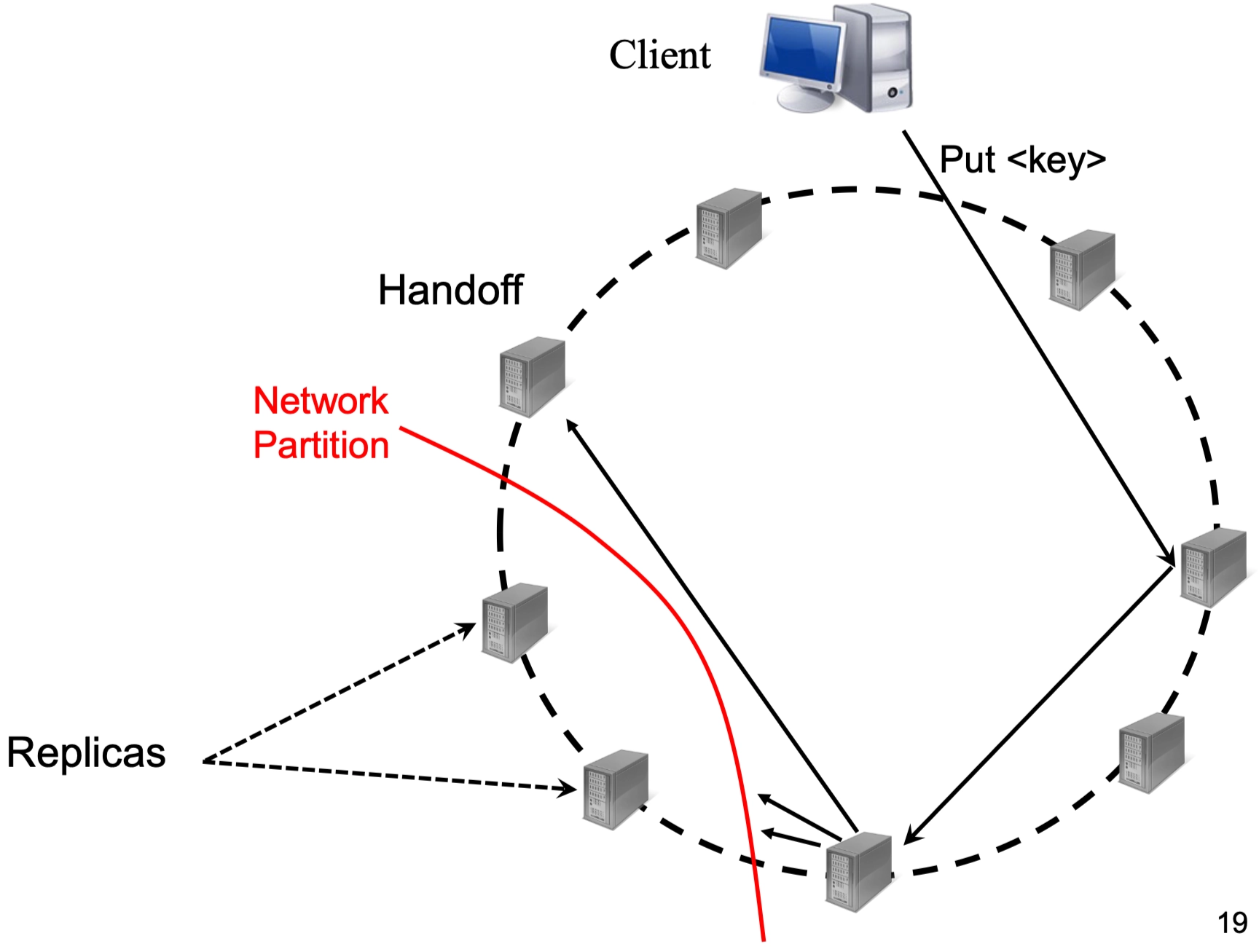
Fault Tolerance and Hinted Handoff¶
Most failures in large-scale systems are transient. Dynamo handles these through a mechanism called Hinted Handoff to maintain the required replication level.
- Transient Failures: If a target node is down, the system replicates the new "Put" object to a handoff node (next available node on the ring, not part of the original \(N\) replicas, which means that no matter what we still need to choose \(N-1\) healthy nodes).
- The Hint: The object is stored with a "hint" indicating which node was the original intended target.
- Multiple failed replicas → multiple hinted nodes
- Monitoring: The handoff node monitors the failed node.
-
Recovery: Once the failed node is back online, the handoff node copies the new objects back to it to restore data durability.
When failed nodes come back:
- Hinted node sends data back
- Deletes its temporary copy
Vector Clock Reconciliation Example¶
Vector clocks allow the system to track the causality of updates and identify branches in data history.
- D1 ([Sx, 1]): Node \(Sx\) handles the first write.
- D2 ([Sx, 2]): Node \(Sx\) handles a second sequential write (D2 succeeds D1).
- Branching: Two different nodes, \(Sy\) and \(Sz\), handle concurrent writes based on D2.
- D3 ([Sx, 2], [Sy, 1])
- D4 ([Sx, 2], [Sz, 1])
- D5 ([Sx, 3], [Sy, 1], [Sz, 1]): During a subsequent read, the client sees D3 and D4 are divergent. The application reconciles them, and a new version D5 is written by node \(Sx\), merging the histories.
- \(Sx\) merged the conflicting versions and then wrote a new version
- Even if the operation is initially a read, if multiple conflicting versions are returned, the system (or client) may perform reconciliation by merging them and writing back a resolved version. This write-back (read repair) is a separate write operation and therefore increments the vector clock.
- Only writes (PUT operations) change the vector clock.
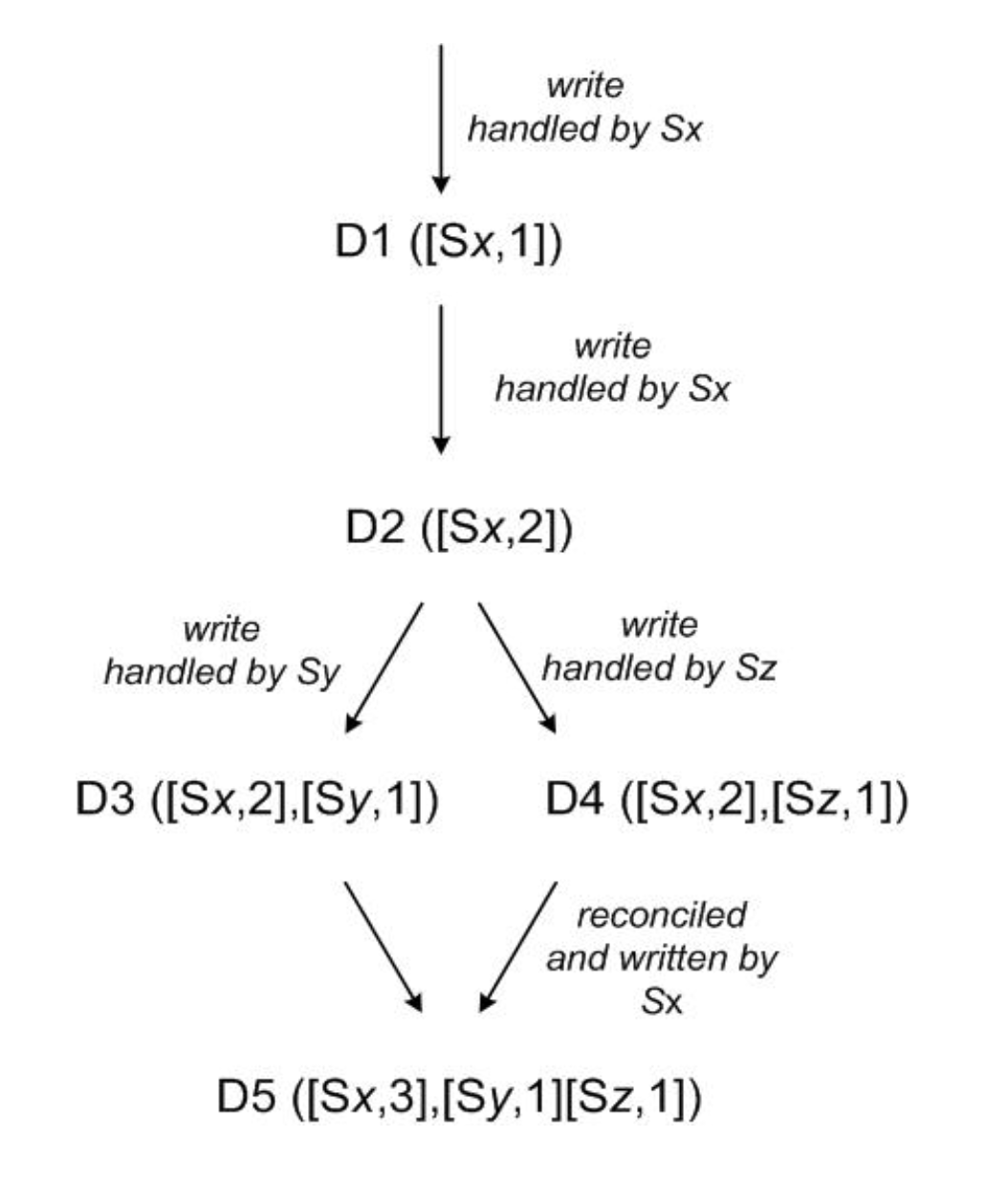
All writes are to the same data item.
Replica Synchronization and Load Balancing¶
Replica Synchronization¶
Replica synchronization is the process of ensuring that different nodes in a distributed system have the same data. This is particularly important when a new node joins or a node recovers from a failure.
The Problem with Simple Deduplication¶
A basic "deduplication protocol" involves sending hashes of all existing keys from one replica to another for comparison.
- Process: Replica A sends hashes of all its keys to the New Node; the New Node compares these against its own disk; it requests the missing data; Replica A sends the keys and context.
- Inefficiency: In a system with 4 TB disks and small 8 KB objects, this results in millions of hashes. Transferring and comparing these individually is extremely slow and "can take a day."
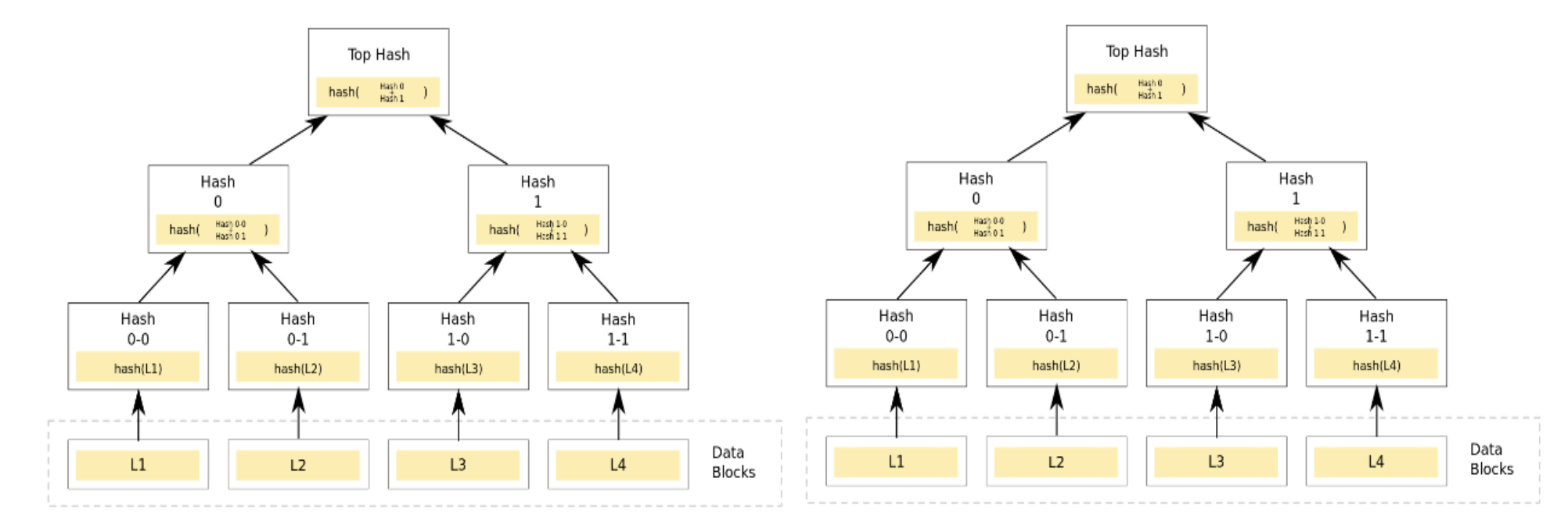
Dynamo Solution: Merkle Trees¶
To solve the overhead of synchronization, Dynamo uses Merkle Trees (hash trees). A Merkle Tree is a hierarchical structure of hashes where each leaf node is a hash of a data block, and every non-leaf node is a hash of its children.
- Hash Tree per Region: Each node maintains a Merkle Tree for the range of keys it hosts.
- Level-by-Level Comparison: Replicas compare the "Top Hash" (root) of their trees.
- If the roots match, the replicas are in sync, and no further data is exchanged.
- If they differ, they compare the children of that node.
- Benefit: This allows the system to quickly pinpoint exactly which specific keys are different without sending all hashes. It results in much less data transfer.
Support for Imbalanced Load and Heterogeneous Nodes¶
In a real-world cluster, nodes often have different hardware capabilities (CPU, RAM, Disk), and data access patterns can be uneven.
Virtual Nodes¶
Dynamo handles this imbalance through the use of Virtual Nodes (vnodes).
- High Multiplicity: Instead of a physical node owning a single large chunk of the hash ring, the system creates \(N\) virtual nodes, where \(N\) is much larger than the number of physical nodes.
- Mapping: These virtual nodes are mapped to physical nodes based on node properties.
- Advantages:
- Load Balancing: If a physical node is powerful, it can host more virtual nodes.
- Flexibility: If a node fails, its load (many small vnodes) is distributed across many other available nodes rather than just one neighbor.